语音AI与语音智能体——图解入门指南(2025版)
原文:Voice AI & Voice Agents: An Illustrated Primer
1. 2025 年的对话式语音 AI¶
LLM 很擅长对话。
如果你花过不少时间与 ChatGPT 或 Claude 进行自由形式的对话,就会直观地感受到:和 LLM 交谈相当自然,而且在很多场景中都很有用。
LLM 也很擅长把非结构化信息转换为结构化数据1。
新的语音 AI 智能体正是利用了 LLM 的这两项能力——对话,以及从非结构化数据中提取结构——来创造一种新的用户体验。
如今,语音 AI 已经被部署到广泛的商业场景中。例如:
- 在医疗预约前收集患者数据
- 跟进 inbound sales leads(入站销售线索)
- 处理越来越多类型的呼叫中心任务
- 协调公司之间的排期与物流
- 以及为几乎所有类型的小企业接听电话
在消费端,对话式语音(以及视频)AI 也开始进入社交应用和游戏。开发者每天都在 GitHub 和社交媒体上分享个人语音 AI 项目与实验。
2. 关于本指南¶
本指南是语音 AI 技术现状的一张快照2。
构建可用于生产环境的语音智能体很复杂。许多组件如果从零实现都并不简单。如果你在构建语音 AI 应用,很可能会依赖某个框架来处理本文讨论的许多事项。不过,无论你是否从零构建所有部件,理解这些组件如何拼装在一起都是有价值的。
本指南直接受到 Sean DuBois 的开源书籍 WebRTC For the Curious 的启发。自四年前首次发布以来,那本书帮助了大量开发者快速理解 WebRTC3。
本文中的语音 AI 代码示例使用 Pipecat 开源框架。Pipecat 是一个面向实时 AI 的、厂商中立的智能体层4。 我们在本文中使用 Pipecat,原因如下:
- 我们每天都用它构建产品,并参与维护,因此对它很熟悉!
- Pipecat 目前是使用最广泛的语音 AI 框架,NVIDIA、Google、AWS、OpenAI 的团队以及数百家初创公司都在使用并贡献这个代码库。
本文尽量提供通用建议,而不是推荐商业产品和服务。当我们提到具体厂商时,是因为它们被相当大比例的语音 AI 开发者使用。
让我们开始吧……
3. 基本的对话式 AI 循环¶
语音 AI 智能体最基本的“待完成工作”是:听人说话,以某种有用的方式回应,然后重复这个序列。
今天的生产级语音智能体几乎都有非常相似的架构。一个语音智能体程序运行在云端,编排 speech-to-speech(语音到语音)循环。该智能体程序使用多个 AI 模型,其中一些在智能体本地运行,一些通过 API 访问。智能体程序还会使用 LLM 函数调用或结构化输出来集成后端系统。
- 用户设备上的麦克风采集语音,编码后通过网络发送给运行在云端的语音智能体程序。
- 输入语音被转录,生成给 LLM 使用的文本输入。
- 文本被组装成上下文——也就是提示词(prompt)——并由 LLM 执行推理。推理输出通常会被智能体程序逻辑过滤或转换5。
- 输出文本被发送给文本转语音(TTS)模型,生成音频输出。
- 音频输出被发送回用户。

你会注意到,语音智能体程序运行在云端,文本转语音、LLM 和语音转文本处理也都发生在云端。从长期看,我们预计会有更多 AI 工作负载运行在设备端。不过今天,生产级语音 AI 仍然高度以云为中心,原因有二:
- 语音 AI 智能体需要使用当前最好的 AI 模型,才能以低延迟可靠地执行复杂工作流。终端用户设备目前还没有足够的 AI 算力,无法以可接受的延迟运行最好的 STT、LLM 和 TTS 模型。
- 今天大多数商业语音 AI 智能体都通过电话与用户沟通。对电话来说,并不存在一个可供你运行代码的终端用户设备——至少不是一个你能在上面运行任何代码的设备!
让我们深入6这个智能体编排世界,并回答如下问题:
- 哪些 LLM 最适合语音 AI 智能体?
- 在长时间会话中,如何管理对话上下文?
- 如何把语音智能体连接到既有后端系统?7
- 如何判断语音智能体表现是否良好?
4. 核心技术与最佳实践¶
4.1. 延迟¶
构建语音智能体在大多数方面都类似于其他类型的 AI 工程。如果你有构建基于文本、多轮 AI 智能体的经验,其中许多经验也适用于语音。
最大的区别是延迟。
人类在正常对话中期望快速响应。500ms 的响应时间很常见。长时间停顿会显得不自然。
如果你在构建语音 AI 智能体,值得学习如何从终端用户视角准确测量延迟。
你经常会看到 AI 平台给出的延迟并不是真正的“voice-to-voice(语音到语音)”测量值。这通常并非恶意。从服务提供方角度看,测量延迟最简单的方法是测量推理时间。因此提供方习惯于这样理解延迟。然而,这种服务器端视角没有计入音频处理、短语端点检测延迟、网络传输以及操作系统开销。
手动测量语音到语音延迟很容易。
只需录下对话,把录音加载到音频编辑器中,查看音频波形,并测量从用户语音结束到 LLM 语音开始之间的时间。
如果你构建面向生产使用的对话式语音应用,偶尔用这种方式 sanity check 一下你的延迟数字是值得的。如果测试时还能加入模拟网络丢包和抖动,则更好!
以编程方式测量真实的语音到语音延迟很有挑战。有些延迟发生在操作系统深处。因此大多数可观测性工具只测量首个(音频)字节时间。这是总语音到语音延迟的一个合理代理指标,但仍需注意,你没有测量的部分——例如短语端点检测变化和网络往返时间——如果无法追踪,可能会成为问题。
如果你在构建对话式 AI 应用,800ms 的语音到语音延迟是一个不错的目标。 下面是从用户麦克风到云端再返回的一次语音到语音往返的拆解。这些数字相当典型,总计约 1s。不过,以今天的 LLM 稳定达到 800ms 仍然具有挑战,虽然并非不可能!
一次语音到语音对话往返的延迟拆解:
| 阶段 | 时间(ms) |
|---|---|
| macOS 麦克风输入 | 40 |
| Opus 编码 | 21 |
| 网络栈与传输 | 10 |
| 数据包处理 | 2 |
| 抖动缓冲区 | 40 |
| Opus 解码 | 1 |
| 转录与端点检测 | 300 |
| LLM TTFB | 350 |
| 句子聚合 | 20 |
| TTS TTFB | 120 |
| Opus 编码 | 21 |
| 数据包处理 | 2 |
| 网络栈与传输 | 10 |
| 抖动缓冲区 | 40 |
| Opus 解码 | 1 |
| macOS 扬声器输出 | 15 |
| 总计 ms | 993 |

我们曾演示过 Pipecat 智能体,通过把所有模型托管在同一个 GPU 集群内,并将所有模型针对延迟而非吞吐优化,实现 500ms 的语音到语音延迟。这种方法今天还未被广泛使用。托管模型很昂贵。而且在语音 AI 中,开放权重 LLM 的使用频率低于 GPT-4o 或 Gemini 这类最好的专有模型。下一节会讨论语音智能体中的 LLM。
由于延迟对语音用例非常重要,本指南后续会反复提到延迟。
4.2. 面向语音用例的 LLM¶
2023 年 3 月 GPT-4 的发布开启了当前这一轮语音 AI 时代。GPT-4 是第一个既能维持灵活的多轮对话,又能通过精确提示执行有用工作的 LLM。今天,GPT-4 的继任者 GPT-4o 仍是对话式语音 AI 的主导模型。
现在,其他几个模型在语音 AI 的关键能力上已经达到或超过了最初的 GPT-4:
但今天的 GPT-4o 本身也优于最初的 GPT-4!尤其是在指令遵循、函数调用和降低幻觉率方面。
GPT-4o 的主要竞争者是 Google 的 Gemini 2.0 Flash。Gemini 2.0 Flash 速度快,指令遵循和函数调用能力与 GPT-4o 相当,且定价激进。
语音 AI 用例的要求很高,因此通常值得使用当前最好的模型。 在某个时间点,这会发生变化,非最先进模型也会足以被广泛用于语音 AI 场景。但现在还不是。
4.2.1 LLM 延迟¶
Claude Sonnet 本可以成为语音 AI 的绝佳选择,只是推理延迟(首个 token 时间,TTFT)并不是 Anthropic 的优先事项。Claude Sonnet 的中位延迟通常是 GPT-4o 和 Gemini Flash 的两倍,P95 分布也宽得多。
OpenAI、Anthropic 和 Google API 的首个 token 时间(TTFT)指标(基于2025 年 5 月):
| 模型 | 中位 TTFT(ms) | P95 TTFT(ms) |
|---|---|---|
| GPT-4o | 460 | 580 |
| GPT-4o mini | 290 | 420 |
| GPT-4.1 | 450 | 670 |
| Gemini 2.0 Flash | 380 | 450 |
| Llama 4 Maverick (Groq) | 290 | 360 |
| Claude Sonnet 3.7 | 1,410 | 2,140 |
一个粗略经验法则:LLM 的首个 token 时间在 500ms 或更低,就足以满足大多数语音 AI 用例。GPT-4o 的 TTFT 通常为 400–500ms。Gemini Flash 也类似。
4.2.2 成本比较¶
推理成本一直在快速且定期下降。因此总体而言,LLM 成本一直是选择哪个 LLM 时最不重要的因素。Gemini 2.0 Flash 新公布的定价相比 GPT-4o 降低了 10 倍成本。它会对语音 AI 格局产生什么影响,还有待观察。
多轮对话的会话成本会随时长超线性增长。30 分钟会话大约比 3 分钟会话贵 100 倍。你可以用缓存、上下文摘要和其他技术降低长会话成本:
| 模型 | 3 分钟对话 | 10 分钟对话 | 30 分钟对话 |
|---|---|---|---|
| GPT-4o | $0.009 | $0.08 | $0.75 |
| Gemini 2.0 Flash | $0.0004 | $0.004 | $0.03 |
注意,成本会随着会话长度超线性增长。除非你在会话过程中裁剪或总结上下文,否则长会话会带来成本问题。对于 speech-to-speech 模型尤其如此(见下文)。
上下文增长的数学规律使得很难确定语音对话的每分钟成本。此外,API 提供商越来越多地提供 token 缓存,这可以抵消成本(并降低延迟),但也让不同用例的成本估算更加复杂。
OpenAI 的 OpenAI Realtime API 自动 token 缓存尤其不错。Google 最近也为其所有 2.5 版本模型推出了类似功能,称为 implicit caching。
4.2.3 开源 / 开放权重¶
Meta 的 Llama 3.3 和 4.0 开放权重模型在基准测试上优于最初的 GPT-4。就今天的商业用例而言,它们总体上还不优于 GPT-4o 和 Gemini。不过,能够基于它们构建并在自己的基础设施上运行,意义重大10。
许多提供商提供 Llama 推理端点,无服务器 GPU 平台也为部署自己的 Llama 提供多种选择。Meta 最近宣布了新的第一方推理 API,并强烈表明开放权重 Llama 模型是公司的关键战略重点。
扩展 Llama 家族中一个有趣且能力很强的模型是 Ultravox。Ultravox 是一个开源的原生音频 LLM。Ultravox 背后的公司也提供企业级托管 speech-to-speech API。Ultravox 使用多种技术把 Llama 3.3 扩展到音频领域,并提升基础模型在语音 AI 用例中的指令遵循和函数调用性能。Ultravox 既展示了开源 AI 生态的好处,也展示了原生音频模型的诱人潜力。
2025 年,我们在开源 / 开放权重模型方面看到了很多进展。Llama 4 刚刚发布,社区仍在评估其在多轮对话式 AI 用例中的实际表现。Alibaba 的新 Qwen 3 模型是优秀的中等规模模型,在早期基准中与 Llama 4 平分秋色。此外,DeepSeek、Google(Gemma)和 Microsoft(Phi)未来的开放权重模型很可能也会成为语音 AI 用例的好选择。
4.2.4 speech-to-speech 模型怎么样?¶
Speech-to-speech 模型是令人兴奋且相对较新的发展。speech-to-speech LLM 可以用音频而非文本作为提示,并能直接生成音频输出。这消除了语音智能体编排循环中的语音转文本(STT)和文本转语音(TTS)部分。
speech-to-speech 模型的潜在好处包括:
- 更低延迟
- 更好理解人类对话细微差别的能力
- 更自然的语音输出
OpenAI 和 Google 都已发布 speech-to-speech API。大多数训练大模型和构建语音 AI 应用的人都认为,speech-to-speech 模型是语音 AI 的未来。
然而,当前的 speech-to-speech 模型和 API 对多数生产级语音 AI 用例而言还不够好。
今天最好的 speech-to-speech 模型听起来确实比今天最好的文本转语音模型更自然。OpenAI 的 gpt4o-audio-preview 11 模型确实像是语音 AI 未来的预览。
不过,speech-to-speech 模型还没有文本模式 LLM 那么成熟和可靠。
- 理论上可以实现更低延迟,但音频使用的 token 比文本多。更大的 token 上下文会让 LLM 处理得更慢。实践中,今天的音频模型在长多轮对话中通常比文本模型更慢12。
- 更好的理解能力似乎确实是这些模型的真实优势。这在 Gemini 2.0 Flash 音频输入上尤其明显。对 gpt-4o-audio-preview 来说,今天的情况稍微不那么明确,因为它是比文本模式 GPT-4o 更小、能力略弱的模型。
- 更自然的语音输出今天已经明显可感知。但音频 LLM 在音频模式下会出现一些文本模式中较少发生的奇怪输出模式:词语重复、有时落入恐怖谷的话语标记,以及偶尔无法完整说完句子。
这些问题中最大的是多轮音频所需的更大上下文大小。既获得原生音频好处、又避免上下文大小缺点的一种折中方法,是把每一轮对话处理为文本和音频的混合:最近一条用户消息使用音频;其余对话历史使用文本。
OpenAI 的 beta speech-to-speech 产品——OpenAI Realtime API——速度很快,语音质量惊人。但该 API 背后的模型是较小的 gpt-4o-audio-preview,而不是完整的 GPT-4o。因此指令遵循和函数调用不如后者。使用 Realtime API 管理对话上下文也比较棘手,而且该 API 还有一些新产品的粗糙边角13。
Google Multimodal Live API 是另一个很有前景、但仍处于早期演进阶段的 speech-to-speech 服务。这个 API 让我们得以一窥 Gemini 模型的近未来:长上下文窗口、优秀的视觉能力、快速推理、强音频理解、代码执行和搜索 grounding。与 OpenAI Realtime API 一样,Multimodal Live API 还不是多数生产级语音 AI 应用的合适选择。
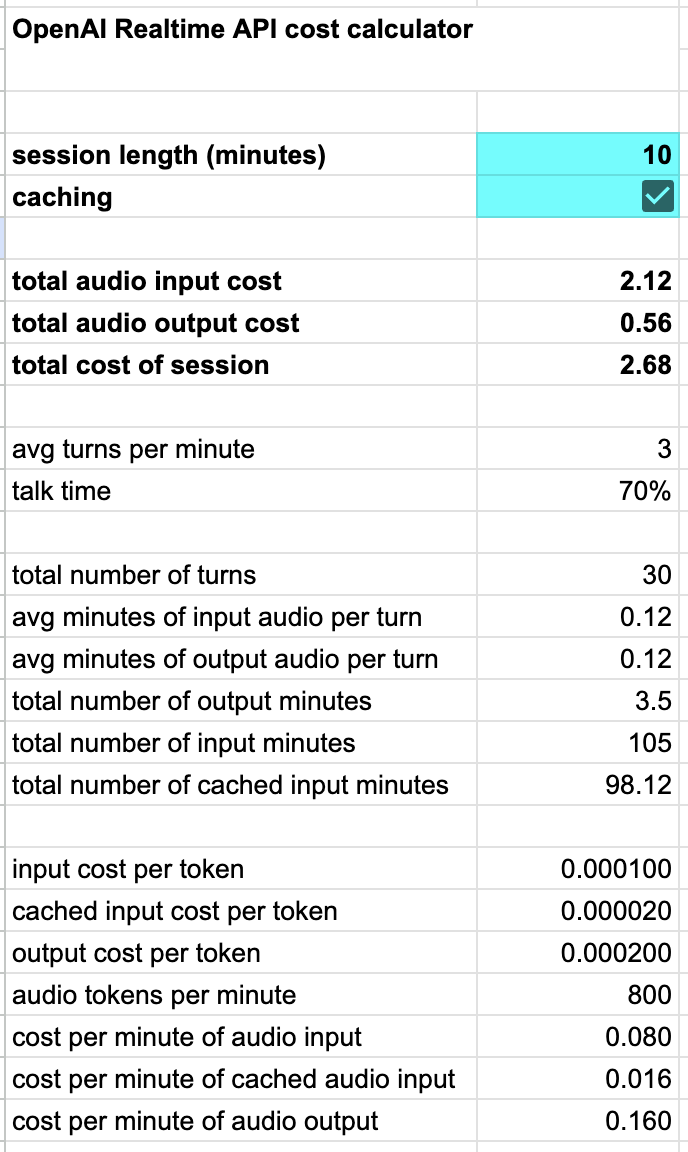
注意,speech-to-speech API 相对昂贵。我们构建了一个 OpenAI Realtime API 计算器,展示在考虑 OpenAI 很好的自动 token 缓存功能后,成本如何随会话长度扩展。
我们预计 2025 年 speech-to-speech 方向会有大量进展。但生产级语音 AI 应用会多快从多模型方法迁移到 speech-to-speech API,仍是一个开放问题。
4.3. 语音转文本¶
语音转文本(STT)是语音 AI 的“输入”阶段。语音转文本也常被称为_转录_或 ASR(automatic speech recognition,自动语音识别)。
对语音 AI 用例来说,我们需要极低的转录延迟和极低的词错误率。遗憾的是,为低延迟优化语音模型会对准确率产生负面影响。
今天有几种非常优秀的转录模型,但它们的架构并非针对低延迟。Whisper 是一个开源模型,被许多产品和服务使用。它非常好,但首个 token 时间通常为 500ms 或更高,因此很少用于对话式语音 AI 用例。
4.3.1 Deepgram 和 Gladia¶
今天大多数生产级语音 AI 智能体使用 Deepgram 或 Gladia 做语音转文本。Deepgram 是一家商业语音转文本 AI 实验室和 API 平台,长期以来在低延迟、低词错误率和低成本之间提供了很好的组合。Gladia 是这个领域的新进入者(成立于 2022 年),尤其擅长多语言支持。
Deepgram 的模型既可以通过自助 API 使用,也可以作为 Docker 容器由客户在自己的系统上运行。多数人一开始会通过 API 使用 Deepgram 语音转文本。对美国用户来说,首个 token 时间通常为 150ms。
管理一个可扩展 GPU 集群是一项持续且重要的 devops 工作,因此从 API 迁移到在自有基础设施上托管模型,不应在没有充分理由的情况下进行。充分理由包括:
- 保持音频 / 转录数据私有。Deepgram 提供 BAA 和数据处理协议,但一些客户会希望完全控制音频和转录数据。美国以外的客户可能有法律义务把数据保留在自己的国家或地区内。(注意,默认情况下 Deepgram 的服务条款允许它们使用你通过 API 发送给它们的所有数据进行训练。企业计划可以选择退出。)
- 降低延迟。Deepgram 在美国以外没有推理服务器。从欧洲访问,Deepgram 的 TTFT 约为 250ms;从印度访问,约为 350ms。
Deepgram 提供微调服务。如果你的用例包含相对少见的词汇、说话风格或口音,这有助于降低词错误率。
在英语世界之外的新语音 AI 项目中,我们最常看到的语音转文本提供商是 Gladia。Gladia 总部位于法国,在美国和欧洲都有推理服务器,并支持 100 多种语言。
Gladia 提供托管 API,也提供在自有基础设施上运行其模型的选项。Gladia 的 API 可用于需要欧洲数据驻留的应用。
4.3.2 提示词可以帮助 LLM¶
相当大比例的转录错误来自实时流中转录模型可用上下文太少。
今天的 LLM 足够聪明,可以绕过转录错误。LLM 执行推理时可以访问完整的对话上下文。因此,你可以告诉 LLM:输入是用户语音的转录,它应据此进行推理。
语音 AI 智能体的提示词示例:
你是一个乐于助人、简洁且可靠的语音助手。你的首要目标是理解用户的口头请求,即使语音转文本的转录中包含错误。你的回答会通过文本转语音系统转换成语音。因此,你的输出必须是纯文本,不能包含格式。
当你收到转录后的用户请求时:
1. 默默修正可能的转录错误。关注用户本意,而不是字面文本。如果某个词在给定上下文中听起来像另一个词,请进行推断和修正。例如,如果转录结果是“明天买牛奶二”,应理解为“明天买牛奶”。
2. 除非用户明确要求更详细的回答,否则请给出简短、直接的回答。例如,如果用户问“现在几点了?”,你应该回答“现在是凌晨 2:38”。如果用户说“讲个笑话”,你应该讲一个短笑话。
3. 始终优先保证清晰和准确。使用纯文本回答,不要使用任何格式、项目符号或多余的寒暄。
4. 如果问题与时间有关,请使用当前日期(2025 年 2 月 3 日)来提供最新信息。
5. 如果你不理解用户请求,请回答:“抱歉,我没有理解。”
你的输出会被直接转换为语音,因此回答应听起来自然,并适合口语对话。
4.3.3 其他语音转文本选项¶
我们预计 2025 年语音转文本领域会出现大量新进展。截至 2025 年 4 月初,我们正在关注的一些新动态包括:
- OpenAI 刚刚发布了两个新的语音转文本模型:gpt-4o-transcribe 和 gpt-4o-mini-transcribe。
- 另外两家备受认可的语音技术公司 Speechmatics 和 AssemblyAI 已开始更关注对话式语音用例,推出具有更快 TTFT 的流式 API 和模型。
- NVIDIA 正在发布开源语音模型,在基准测试上表现极佳。
- 推理公司 Groq 托管的 Whisper Large v3 Turbo 版本现在中位 TTFT 低于 300ms,进入了可作为对话式语音应用选项的范围。这是我们见过第一个达到这种延迟的 Whisper API 服务。
所有大型云服务都有语音转文本 API。但就今天的低延迟语音 AI 用例而言,它们都不如 Deepgram 或 Gladia。
不过,如果符合以下情况,你可能会想使用 Azure AI Speech、Amazon Transcribe 或 Google Speech-to-Text:
- 你已经与这些云提供商之一有大量承诺消费或数据处理安排。
- 你有很多这些云提供商的 startup credits 要花!
4.3.4 使用 Google Gemini 进行转录¶
利用 Gemini 2.0 Flash 作为低成本原生音频模型优势的一种方式,是同时使用 Gemini 2.0 进行对话生成和转录。
为此,我们需要运行两个并行推理过程。
- 一个推理过程生成对话响应。
- 另一个推理过程转录用户语音。
- 每段音频输入只用于一轮。完整对话上下文始终是最近用户语音的音频,加上所有之前输入和输出的文本转录。
- 这让你获得两全其美的效果:当前用户话语使用原生音频理解;整体上下文降低 token 数14。
下面是以 Pipecat pipeline 实现这些并行推理过程的代码。
pipeline = Pipeline([
transport.input(),
audio_collector,
context_aggregator.user(),
ParallelPipeline(
[ # transcribe
input_transcription_context_filter,
input_transcription_llm,
transcription_frames_emitter,
],
[ # conversation inference
conversation_llm,
],
),
tts,
transport.output(),
context_aggregator.assistant(),
context_text_audio_fixup,
])
逻辑如下:
- 对话 LLM 接收文本形式的对话历史,加上每一轮新的用户语音原生音频,并输出对话响应
- 输入转录 LLM 接收同样的输入,但输出最近用户语音的逐字转录
- 在每轮对话结束时,用户音频上下文条目被该音频的转录替换
Gemini 的每 token 成本非常低,因此这种方法实际上比使用 Deepgram 做转录更便宜。
重要的是要理解:这里我们并没有把 Gemini 2.0 Flash 当作完整的 speech-to-speech 模型使用,但我们_确实_使用了它的原生音频理解能力。我们通过提示模型,让它运行在两种不同“模式”下:对话和转录。
以这种方式使用 LLM 展示了 SOTA LLM 架构和能力的强大。这种方法还足够新,仍属实验性,但早期测试表明,它可能比任何当前技术都带来更好的对话理解和更准确的转录。不过也有缺点。转录延迟不如专用语音转文本模型。运行两个推理过程并交换上下文元素的复杂度很高。通用 LLM 会受到提示注入和上下文跟随错误的影响,而专用转录模型没有这些脆弱性。
下面是用于转录的系统指令(提示词):
你是一个音频转录器。你正在接收来自用户的音频。你的任务是把输入音频准确转录为文本,完全按照用户实际说出的内容转写。
在音频输入之前,你会收到完整的对话历史,以帮助理解上下文。完整历史只应用于提高转录准确性。
规则:
- 只回答音频输入的准确转录。
- 不要包含转录之外的任何文本。
- 不要解释,也不要补充回答。
- 简洁、精确地转录音频输入。
- 如果音频不清晰,输出特殊字符串 ""。
- 除准确转录或 "" 之外,不允许任何其他回答。
4.4. 文本转语音¶
文本转语音(TTS)是语音到语音处理循环的输出阶段。
语音 AI 开发者会基于以下因素选择语音模型 / 服务:
2024 年,语音选项显著扩展。新的初创公司出现。最佳语音质量大幅提升。每个提供商都改进了延迟。
与语音转文本类似,所有大型云提供商都有文本转语音产品17。 但多数语音 AI 开发者没有使用它们,因为当前初创公司的模型更好。
在实时对话式语音模型方面最有 traction 的实验室包括(按字母顺序):
- Cartesia —— 使用创新的状态空间模型架构,同时实现高质量和低延迟
- Deepgram —— 优先考虑延迟和低成本
- ElevenLabs —— 强调情感和上下文真实感
- Rime —— 提供完全基于对话语音训练的可定制 TTS 模型
这四家公司都有强大的模型、工程团队,以及稳定且性能良好的 API。Cartesia、Deepgram 和 Rime 的模型可以部署在你自己的基础设施上。
| 每分钟成本(约) | 中位 TTFB(ms) | P95 TTFB(ms) | 平均发声前 ms | |
|---|---|---|---|---|
| Cartesia | $0.02 | 190 | 260 | 160 |
| Deepgram | $0.008 | 150 | 320 | 260 |
| ElevenLabs Turbo v2 | $0.08 | 300 | 510 | 160 |
| ElevenLabs Flash v2 | $0.04 | 170 | 190 | 100 |
| Rime | $0.024 | 340 | 980 | 160 |
每分钟近似成本(规模化情况下)和首字节时间指标——2025 年 2 月。注意,成本取决于承诺用量和使用的功能。平均发声前毫秒数是音频流中第一帧语音前的平均初始静音间隔。
与语音转文本一样,非英语语音模型的质量和支持存在很大差异。如果你为非英语用例构建语音 AI,可能需要做更广泛的测试——测试更多服务和更多声音,才能找到满意的方案。
所有语音模型有时都会读错词,也未必知道专有名词或少见词的读法。
有些服务提供控制发音的能力。如果你预先知道文本输出会包含特定专有名词,这会很有帮助。如果你的语音服务不支持音素控制,可以提示 LLM 输出特定词的“sounds-like”拼写。例如,用 in-vidia 代替 NVIDIA。
通过 LLM 文本输出来控制发音的示例提示词:
对于对话式语音用例,能够追踪用户实际听到了哪些文本,对于维护准确的对话上下文很重要。这要求模型在生成音频的同时生成词级时间戳元数据,并且时间戳数据能够反向重建到原始输入文本。这是语音模型相对较新的能力。上表中除 ElevenLabs Flash 外的所有模型都支持词级时间戳。
Cartesia API 返回的词级时间戳:
{
"type": "timestamps",
"context_id": "test-01",
"status_code": 206,
"done": false,
"word_timestamps": {
"words": ["What's", "the", "capital", "of", "France?"],
"start": [0.02, 0.3, 0.48, 0.6, 0.8],
"end": [0.3, 0.36, 0.6, 0.8, 1]
}
}
此外,一个非常扎实的实时流式 API 也很有帮助。对话式语音应用经常并行触发多个音频推理。语音智能体代码需要能够中断正在进行的推理,并将每个推理请求关联到输出流。语音模型提供商的流式 API 都相对较新,仍在演进。目前,Cartesia 和 Rime 在 Pipecat 中拥有最成熟的流式支持。
我们预计 2025 年语音模型会继续进步。
- 上述几家公司都暗示今年上半年会有新模型。
- OpenAI 最近发布了一个新的文本转语音模型 gpt-4o-mini-tts。这个模型完全可控制,这为告诉语音模型不仅说_什么_、还要_怎么_说打开了新可能。你可以在 openai.fm 体验控制 gpt-4o-mini-tts。
- Groq 和 PlayAI 最近宣布合作。Groq 以快速推理著称,PlayAI 提供支持 30 多种语言的低延迟语音模型。
4.5. 音频处理¶
一个好的语音 AI 平台或库会基本隐藏音频采集与处理的复杂性。但如果你构建复杂的语音智能体,迟早会遇到音频处理中的 bug 和边界情况18。 因此,快速了解一下音频输入流水线是值得的。
4.5.1 麦克风与自动增益控制¶
今天的麦克风是极其复杂的硬件设备,并与大量低层软件耦合。这通常很好——我们能从移动设备、笔记本电脑和蓝牙耳机中的微型麦克风获得很棒的音频。
但有时这些低层软件不会按我们的期望工作。尤其是蓝牙设备可能会给语音输入增加几百毫秒延迟。作为语音 AI 开发者,这在很大程度上超出你的控制。但值得意识到,延迟会因特定用户的操作系统和输入设备而有很大差异。

多数音频采集流水线会对输入信号应用一定程度的自动增益控制。同样,这通常是你想要的,因为它可以补偿用户距离麦克风远近等因素。你通常可以禁用一部分自动增益控制,但在消费级设备上通常无法完全禁用。
4.5.2 回声消除¶
如果用户把手机贴在耳边,或戴着耳机,你不需要担心本地麦克风和扬声器之间的反馈。但如果用户使用免提电话,或使用没有耳机的笔记本电脑,那么良好的回声消除极其重要。
回声消除对延迟非常敏感,因此必须在设备上运行(而不是在云端)。今天,电话技术栈、Web 浏览器和 WebRTC 原生移动 SDK 都内置了出色的回声消除19。
因此,如果你使用语音 AI、WebRTC 或电话 SDK,几乎所有真实场景下都应该能依赖回声消除“正常工作”。如果你自己实现语音 AI 采集流水线,就需要弄清楚如何集成回声消除逻辑。例如,如果你在构建基于 WebSocket 的 React Native 应用,默认不会有任何回声消除20。
4.5.3 降噪、语音与音乐¶
电话和 WebRTC 的音频采集流水线几乎总是默认使用“语音模式”。语音可以比音乐被压缩得更多,而且对于较窄频带信号,降噪和回声消除算法更容易实现。
许多电话平台只支持 8kHz 音频。以现代标准看,这明显是低质量。如果你必须路由经过这种受限系统,那么对此无能为力。用户可能会注意到质量,也可能不会——大多数人对电话音频的期待本来就不高。
WebRTC 支持非常高质量的音频21。 默认 WebRTC 设置通常是 48kHz 采样率、单声道、32 kbps Opus 编码,以及中等强度降噪算法。这些设置针对语音优化。它们适用于广泛的设备和环境,通常是语音 AI 的正确选择。
音乐在这些设置下听起来不会好!
如果你需要通过 WebRTC 连接发送音乐,你会希望:
- 关闭回声消除(用户需要佩戴耳机)。
- 关闭降噪。
- 可选地启用立体声。
-
提高 Opus 编码码率(单声道 64 kbps 是不错目标,立体声为 96 kbps 或 128 kbps)。
-
与 LLM 老师进行音乐课。
- 录制包含背景声或音乐的播客。
- 交互式生成 AI 音乐。
4.5.4 编码¶
编码是描述音频数据如何格式化以便通过网络连接发送的通用术语22。
实时通信中的常见编码包括:
- 16-bit PCM 格式的未压缩音频。
- Opus —— WebRTC 和一些电话系统。
- G.711 —— 一种得到广泛支持的标准电话编解码器。
语音 AI 最常用的音频编解码器:
| 编解码器 | 码率 | 质量 | 使用场景 |
|---|---|---|---|
| 16-bit PCM | 384 kbps(单声道 24 kHz) | 非常高(近似无损) | 语音录制、嵌入式系统、简单解码至关重要的环境 |
| Opus 32 kbps | 32 kbps | 良好(针对语音优化的心理声学压缩) | 视频通话、低带宽流媒体、播客 |
| Opus 96 kbps | 96 kbps | 很好到优秀(心理声学压缩) | 流媒体、音乐、音频归档 |
| G.711 (8 kHz) | 64 kbps | 较差(带宽受限、以语音为中心) | 传统 VoIP 系统、电话、传真传输、语音消息 |
在这三个选项中,Opus 远远最好。Opus 内置于 Web 浏览器,从一开始就被设计为低延迟编解码器,且非常高效。它在广泛码率范围内表现良好,同时支持语音和高保真用例。
16-bit PCM 是“原始音频”。你可以直接把 PCM 音频帧发送给软件声音通道(假设采样率和数据类型指定正确)。不过要注意,这种未压缩音频通常不是你想通过互联网连接发送的内容。24kHz PCM 的码率为 384 kbps。这个码率已经足够大,许多来自终端用户设备的真实连接会难以实时传输这些字节。
4.5.5 服务端噪声处理与说话人隔离¶
语音转文本和语音活动检测(VAD)模型通常可以忽略一般环境噪声——街道声音、狗叫、靠近麦克风的大风扇声、键盘点击声。因此,对许多人到人用例很关键的传统“降噪”算法,对语音 AI 并没有那么关键。
但有一种音频处理对语音 AI 特别有价值:主说话人隔离。主说话人隔离会抑制背景语音。这可以显著提升转录准确率。
想象一下,你在机场这样的环境中与语音智能体交谈。手机麦克风很可能会捕捉到来自登机口广播和路人的大量背景语音。你当然不希望这些背景语音出现在 LLM 看到的文本转录中!
或者想象用户在客厅里,背景中开着电视或收音机。因为人类通常很擅长过滤低音量背景语音,所以人们在拨打客服热线前未必会想到关掉电视或收音机。
目前可用于自有语音 AI 流水线的最佳说话人隔离模型由 Krisp 销售。许可证面向企业用户,并不便宜。但对于规模化商业用例,语音智能体性能提升足以证明其成本合理。
OpenAI 最近在 Realtime API 中发布了新的降噪功能。参考文档在这里。
pipeline = Pipeline([
transport.input(),
krisp_filter,
vad_turn_detector,
stt,
context_aggregator.user(),
llm,
tts,
transport.output(),
context_aggregator.assistant(),
])
带有 Krisp 处理元素的 Pipecat pipeline
4.5.6 语音活动检测¶
几乎每个语音 AI 流水线都会包含一个语音活动检测阶段。VAD 会把音频片段分类为“语音”和“非语音”。我们将在下面的轮次检测一节详细讨论 VAD。
4.6. 网络传输¶
4.6.1 WebSockets 与 WebRTC¶

AI 服务都会使用 WebSockets 和 WebRTC 进行音频流传输。
WebSockets 很适合服务器到服务器的用例。对于延迟不是首要关注点的场景,以及原型开发和一般 hacking,它也没问题。
生产环境中,不应把 WebSockets 用于客户端-服务器实时媒体连接。
如果你在构建浏览器或原生移动应用,并且对话式延迟对你的应用很重要,你应该使用 WebRTC 连接从应用发送和接收音频。
WebSockets 在终端用户设备与服务之间进行实时媒体传输的主要问题包括:
- WebSockets 基于 TCP,因此音频流会受到队头阻塞影响。
- WebRTC 使用的 Opus 音频编解码器与 WebRTC 的带宽估计和包发送节奏(拥塞控制)逻辑紧密耦合,这使 WebRTC 音频流能够抵御广泛的真实网络行为,而这些行为会导致 WebSocket 连接积累延迟。
- Opus 音频编解码器具有很好的前向纠错能力,使音频流能够抵御相当高比例的丢包。(不过,只有当你的网络传输可以丢弃迟到数据包且不做队头阻塞时,这才有帮助。)
- WebRTC 音频会自动带时间戳,因此播放和中断逻辑都很简单。
- WebRTC 包含详细性能和媒体质量统计的 hooks。一个好的 WebRTC 平台会提供详细 dashboard 和分析。这种可观测性对 WebSockets 来说介于非常难和不可能之间。
- WebSocket 重连逻辑很难健壮实现。你必须构建一个 ping/ack 框架(或者充分测试并理解你的 WebSocket 库提供的框架)。TCP 超时和连接事件在不同平台上的行为不同。
- 最后,今天优秀的 WebRTC 实现都带有非常好的回声消除、降噪和自动增益控制。
你可以用两种方式使用 WebRTC:
- 通过云端 WebRTC 服务器路由。
- 在客户端设备和语音 AI 进程之间建立直接连接。
通过云服务器路由在许多真实用例中表现更好(见下文网络路由)。云基础设施还使直接连接难以轻松或可扩展支持的一系列功能成为可能(多参与者会话、与电话系统集成、录制)。
但“serverless” WebRTC 也适合许多语音 AI 用例。Pipecat 通过 SmallWebRTCTransport 类支持 serverless WebRTC。Hugging Face 的 FastRTC 等框架也完全围绕这种网络模式构建。
4.6.2 HTTP¶
HTTP 对语音 AI 仍然有用且重要!HTTP 是互联网上服务互联的通用语言。REST API 是 HTTP。Webhooks 也是 HTTP。
面向文本的推理通过 HTTP 发生,因此语音 AI 流水线通常会通过 HTTP API 调用对话循环中的 LLM 部分。
语音智能体在与外部服务和内部 API 集成时也使用 HTTP。一个有用技术是把 LLM 函数调用代理到 HTTP 端点。这可以解耦语音 AI 智能体代码和 devops 与函数实现。
多模态 AI 应用通常会希望同时实现 HTTP 和 WebRTC 代码路径。想象一个同时支持文本模式和语音模式的聊天应用。对话状态需要能通过任一连接路径访问,这会影响客户端和服务端代码(例如 Kubernetes pods 和 Docker containers 如何架构)。
HTTP 的两个缺点是延迟,以及实现长期存在的双向连接很困难:
- 建立加密 HTTP 连接需要多次网络往返。媒体连接建立时间要显著低于 30ms 相当困难,即使对高度优化的服务器,现实中的首字节发送时间也更接近 100ms。
- 长期存在的双向 HTTP 连接足够难管理,以至于你通常最好直接使用 WebSockets。
- HTTP 是基于 TCP 的协议,因此影响 WebSockets 的相同队头阻塞问题也会影响 HTTP。
- 通过 HTTP 发送原始二进制数据并不常见,因此多数 API 会选择对二进制数据进行 base64 编码,这会增加媒体流码率。
这就引出了 QUIC……
一个同时使用 HTTP 和 WebRTC 进行网络通信的语音 AI 智能体:

4.6.3 QUIC 与 MoQ¶
QUIC 是一种新的网络协议,设计目标是成为最新版 HTTP(HTTP/3)的传输层,同时也灵活支持其他互联网规模用例。
QUIC 是基于 UDP 的协议,解决了上述 HTTP 的所有问题。使用 QUIC,你可以获得更快的连接时间、双向流,以及没有队头阻塞。Google 和 Facebook 一直在稳步推出 QUIC,因此如今你的一些 HTTP 请求会以 UDP 而非 TCP 数据包形式穿越互联网23。
QUIC 将成为互联网媒体流未来的重要组成部分。不过,实时媒体流迁移到基于 QUIC 的协议还需要时间。构建基于 QUIC 的语音智能体的一个障碍是,Safari 尚未支持 WebSockets 的 QUIC 演进版本 WebTransport。
IETF Media over QUIC 工作组24旨在开发一种“用于媒体采集和分发的简单低延迟媒体交付方案”。与所有标准一样,用最简单的构件支持尽可能广泛的重要用例并不容易。人们对使用 QUIC 做点播视频流、大规模视频广播、直播视频流、大量参与者的低延迟会话,以及低延迟 1:1 会话都很兴奋。
实时语音 AI 用例正好在合适的时间增长,有机会影响 MoQ 标准的发展。
4.6.4 网络路由¶
无论底层网络协议是什么,长距离网络连接都会给延迟和实时媒体可靠性带来问题。
对于实时媒体交付,你希望服务器尽可能靠近用户。
例如,从英国用户到 AWS us-west-1(北加州)服务器的往返包时间通常约为 140ms。相比之下,同一用户到 AWS eu-west-2 的 RTT 通常为 15ms 或更低。

英国用户到 AWS us-west-1 的 RTT 比到 AWS eu-west-2 多约 100ms
这相差超过 100ms——如果你的语音到语音延迟目标是 1,000ms,这就是延迟“预算”的 10%。
边缘路由
你可能无法把服务器部署到所有用户附近。
要让全球所有用户都达到 15ms RTT,至少需要部署到 40 个全球数据中心。这是一项很大的 devops 工作。如果你运行需要 GPU 的工作负载,或依赖自身并未全球部署的服务,这甚至可能不可能。
你无法欺骗光速。25 但你可以尝试避免路由变化和拥塞。
关键是让公共互联网路由尽可能短。把用户连接到离他们近的边缘服务器。之后使用私有路由。
这种边缘路由可以降低中位包 RTT。英国 → 北加州通过私有骨干网的路由可能约为 100ms。100ms(长距离私有路由)+ 15ms(公共互联网第一跳)= 115ms。这个私有路由中位 RTT 比公共路由中位 RTT 好 25ms。

从英国到 AWS us-west-1 的边缘路由。通过公共网络的第一跳 RTT 仍为 15ms。但经私有网络到北加州的长路径 RTT 为 100ms。总 RTT 为 115ms,比英国到 us-west-1 的公共路由快 25ms。它的可变性也显著更低(丢包更少、抖动更低)。
不过,比中位 RTT 改进更关键的是交付可靠性的提升和更低的抖动26。 私有路由的 P95 RTT 会显著低于公共路由的 P9527。
这意味着,经过长距离公共路由的实时媒体连接,会比使用私有路由的连接明显更卡顿。回想一下,我们试图尽快交付每个音频包,但必须按顺序播放音频包。单个延迟包会迫使我们扩大抖动缓冲区,在延迟包到达之前保留其他已收到的包(或者直到我们决定它耗时太久,然后用高级数学或有毛刺的音频样本填补空缺)。

好的 WebRTC 基础设施提供商会提供边缘路由。他们应能向你展示服务器集群位置,并提供展示其私有路由性能的指标。
4.7. 轮次检测¶
轮次检测 指判断用户何时说完并期望 LLM 回应。
在学术文献中,这个问题的不同方面被称为 短语检测、语音分割和端点检测。(存在相关学术文献这一事实说明:这不是一个简单问题。)
我们(人类)每次与别人交谈时都在做轮次检测。而且我们并不总是做对!28
因此,轮次检测是一个困难问题,没有完美解决方案。不过,让我们讨论几种常用方法。
4.7.1 语音活动检测¶
目前,语音 AI 智能体做轮次检测最常见的方法,是假设较长停顿意味着用户已经说完。
语音 AI 智能体流水线使用小型专用语音活动检测模型识别停顿。VAD 模型被训练用来把音频片段分类为语音或非语音。(这比仅根据音量级别识别停顿稳健得多。)
你可以在语音 AI 连接的客户端侧或服务器侧运行 VAD。如果你本来就需要在客户端做大量音频处理,可能需要在客户端运行 VAD 以支持这些处理。例如,也许你在嵌入式设备上识别唤醒词,只有当你在短语开头检测到唤醒词时才通过网络发送音频。Hey, Siri …
不过一般来说,把 VAD 作为语音 AI 智能体处理循环的一部分运行会稍微简单一些。如果用户通过电话连接,你没有可运行 VAD 的客户端,因此必须在服务器上做。
语音 AI 中最常用的 VAD 模型是 Silero VAD。这个开源模型在 CPU 上高效运行,支持多语言,对 8kHz 和 16kHz 音频都表现良好,并提供 wasm 包可在 Web 浏览器中使用。在实时单声道音频流上运行 Silero,通常消耗不到典型虚拟机 CPU 核心的 ⅛。

轮次检测算法会有几个配置参数:
- 判定轮次结束所需的停顿长度
- 触发开始说话事件所需的语音片段长度
- 将每个音频片段分类为语音的置信度
- 语音片段的最小音量
# Pipecat's names and default values
# for the four configurable VAD
# parameters
VAD_STOP_SECS = 0.8
VAD_START_SECS = 0.2
VAD_CONFIDENCE = 0.7
VAD_MIN_VOLUME = 0.6
针对具体用例调优这些参数,可以显著改善轮次检测行为。
4.7.2 按键说话¶
基于语音停顿做轮次检测的明显问题是:有时人会停顿,但还没说完。
个人说话风格各不相同。人在某些类型的对话中会比其他对话停顿更多。
设置较长停顿间隔会造成生硬对话——非常糟糕的用户体验。但如果停顿间隔较短,语音智能体会频繁打断用户——同样是糟糕体验。
基于停顿的轮次检测最常见替代方案是按键说话。按键说话意味着要求用户开始说话时按下或按住按钮,说完时再次按下按钮或松开按钮。(想想老式对讲机如何工作。)
按键说话下轮次检测毫无歧义。但用户体验不等同于自然交谈。
按键说话不适用于电话语音 AI 智能体。
4.7.3 端点标记¶
你也可以使用特定词语作为轮次结束标记。(想想卡车司机在 CB radio 上说 “over”。)
识别特定端点标记最简单的方法,是对每个转录片段运行正则表达式匹配。但也可以用小型语言模型检测端点词或短语。
使用显式端点标记的语音 AI 应用相当少见。用户必须学会如何和这些应用说话。但这种方法对专门用例可能非常有效。
例如,去年我们看到一个不错的演示:有人把写作助手作为副项目给自己构建。他们使用多种命令短语来指示轮次端点并在模式之间切换。
4.7.4 上下文感知轮次检测(semantic VAD 与 smart turn)¶
人类做轮次检测时,会使用多种线索:
- 识别 “um” 等填充词,这通常表示说话还会继续。
- 语法结构。
- 对模式的了解,例如电话号码有特定位数。
- 语调和发音模式,例如在停顿前拉长最后一个词。
深度学习模型非常擅长识别模式。LLM 拥有大量潜在语法知识,可以通过提示执行短语端点检测。更小的专用分类模型可以基于语言、语调和发音模式训练。
随着语音智能体商业重要性越来越高,我们预计会看到新的上下文感知语音 AI 轮次检测模型。
主要有两种方法:
- 训练一个可实时运行的小型轮次检测模型。将该模型与 VAD 模型结合使用,或替代 VAD 模型。轮次检测模型可以被训练为在文本上做模式匹配。文本模式轮次检测模型在转录后内联运行于处理流水线中,通常需要基于特定转录模型的输出训练才有效。或者,轮次检测模型也可以被训练为直接处理原生音频,这使轮次检测分类能够同时考虑语言层模式以及语调、语速和发音模式。原生音频轮次检测模型不需要任何转录信息,因此可以与转录并行运行,从而提升性能。
- 使用大型 LLM 和 few-shot prompt 执行轮次检测。大型 LLM 通常太慢,无法内联使用并阻塞流水线。为绕过这一点,你可以拆分流水线,并行执行轮次检测和“贪婪”对话推理。
[
transport.input(),
vad,
audio_accumulater,
ParallelPipeline(
[
FunctionFilter(filter=block_user_stopped_speaking),
],
[
ParallelPipeline(
[
classifier_llm,
completeness_check,
],
[
tx_llm,
user_aggregator_buffer,
],
)
],
[
conversation_audio_context_assembler,
conversation_llm,
bot_output_gate,
],
),
tts,
transport.output(),
context_aggregator.assistant(),
],
使用 Gemini 2.0 Flash 原生音频输入进行上下文感知轮次检测的 Pipecat pipeline 代码。轮次检测和贪婪对话推理并行运行。输出会被 gate,直到轮次检测推理检测到短语端点。
轮次检测的一些近期进展:
- 3 月,OpenAI 为 Realtime API 发布了新的上下文感知轮次检测能力。他们称该功能为 semantic VAD,以区别于更简单的 server VAD(基于停顿的轮次检测)。文档在这里。
- Tavus 开发了基于 transformer 的原生音频轮次检测模型,现在是其实时对话视频 API 的一部分。Tavus 团队发布了一篇非常好的技术概览,介绍问题空间和模型工作方式。
- Smart Turn 开源模型是由 Pipecat 社区构建和维护的 SOTA 原生音频轮次检测模型。所有训练数据、训练代码、推理代码和模型权重都是开源的29。
4.8. 中断处理¶
_中断处理_指允许用户打断语音 AI 智能体。打断是对话的正常组成部分,因此优雅处理中断很重要。
要实现中断处理,你需要流水线的每个部分都可取消。你还需要能够非常快速地停止客户端音频播放。
一般来说,你使用的框架会在触发中断时负责停止所有处理。但如果你直接使用会以快于实时速度向你发送原始音频帧的 API,就必须手动停止播放并刷新音频缓冲区。
4.8.1 避免误中断¶
有几个意外中断来源值得注意。
- 被分类为语音的瞬时噪声。好的 VAD 模型能很好地区分语音和“噪声”。但某些短促、尖锐的初始音频在出现在话语开头时,会带有中等语音置信度。咳嗽和键盘点击都属于这一类。你可以调整 VAD 起始片段长度和置信度来尽量减少这类中断。权衡是,延长起始片段长度并提高置信度阈值,会给那些你确实希望检测为完整话语的非常短短语造成问题30。
- 回声消除失败。回声消除算法并不完美。从静音切换到语音播放尤其具有挑战。如果你做过很多语音智能体测试,可能听过 bot 在刚开始说话时打断自己。罪魁祸首是回声消除让一小段初始语音音频反馈进了麦克风。最小 VAD 起始片段长度有助于避免这个问题。对音量级别应用指数平滑31以避免剧烈音量跳变也有帮助。
- 背景语音。VAD 模型不会区分用户语音和背景语音。如果背景语音高于你的音量阈值,就会触发中断。说话人隔离音频处理步骤可以减少背景语音造成的误中断。见上文服务端噪声处理与说话人隔离一节。
4.8.2 中断后保持准确上下文¶
由于 LLM 生成输出快于实时,当中断发生时,你通常会有已排队等待发送给用户的 LLM 输出。
通常,你希望对话上下文匹配用户实际听到的内容(而不是你的流水线快于实时生成的内容)。
你可能也会把对话上下文保存为文本32。
因此,你需要一种方式弄清用户实际 听到了! 哪些文本。
最好的文本转语音服务可以报告词级时间戳数据。使用这些词级时间戳来缓冲和组装与用户听到的音频相匹配的助手消息文本。见上文文本转语音一节中关于词级时间戳的讨论。Pipecat 会自动处理这一点。
4.9. 管理对话上下文¶
LLM 是无状态的。这意味着,对于多轮对话,你需要在每次生成新响应时,把所有之前的用户和智能体消息——以及其他配置元素——重新喂给 LLM。
每一轮都向 LLM 发送完整对话历史:
Turn 1:
User: What's the capital of France?
LLM: The capital of France is Paris.
Turn 2:
User: What's the capital of France?
LLM: The capital of France is Paris.
User: Is the Eiffel Tower there?
LLM: Yes, the Eiffel Tower is in Paris.
Turn 3:
User: What's the capital of France?
LLM: The capital of France is Paris.
User: Is the Eiffel Tower there?
LLM: Yes, the Eiffel Tower is in Paris.
User: How tall is it?
LLM: The Eiffel Tower is about 330 meters tall.
对于每次推理操作——也就是每一轮对话——你可以向 LLM 发送:
- 系统指令
- 对话消息
- 供 LLM 使用的工具(函数)
- 配置参数(例如 temperature)
4.9.1 LLM API 之间的差异¶
今天所有主流 LLM 的总体设计都是一样的。
但不同提供商的 API 之间存在差异。OpenAI、Google 和 Anthropic 都有不同的消息格式、工具 / 函数定义结构差异,以及系统指令指定方式的差异。
有第三方 API 网关和软件库会把 API 调用转换为 OpenAI 的格式。这很有价值,因为能够在不同 LLM 之间切换很有用。但这些服务并不总能正确抽象这些差异。新功能,以及每个 API 独有的功能,并不总是被支持。(有时翻译层还会有 bug。)
在 AI 工程仍处于相对早期的今天,要不要抽象仍是一个问题33。
例如,Pipecat 会针对上下文消息和工具定义,把消息转换为 OpenAI 格式或从 OpenAI 格式转换回来。但是否以及如何这样做,曾是社区大量讨论的主题!34
4.9.2 在轮次之间修改上下文¶
必须管理多轮上下文会增加开发语音 AI 智能体的复杂性。另一方面,能够追溯性地修改上下文也很有用。对每一轮对话,你都可以精确决定向 LLM 发送什么。
LLM 并不总是需要完整对话上下文。缩短或总结上下文可以降低延迟、降低成本,并提高语音 AI 智能体的可靠性。关于这个主题,见下文脚本化与指令遵循一节。
4.10. 函数调用¶
生产级语音 AI 智能体高度依赖 LLM 函数调用。函数调用用于:
- 为检索增强生成(RAG)获取信息
- 与既有后端系统和 API 交互
- 与电话技术栈集成——呼叫转接、排队、发送 DTMF 音
- 脚本遵循——实现工作流状态转换的函数调用
4.10.1 语音 AI 语境中的函数调用可靠性¶
随着语音 AI 智能体被部署到越来越复杂的用例中,可靠的函数调用变得越来越重要。
SOTA LLM 在函数调用方面稳步变好,但语音 AI 用例往往会把 LLM 函数调用能力推到极限。
语音 AI 智能体倾向于:
- 在多轮对话中使用函数。在多轮对话中,随着每轮加入用户和助手消息,提示会变得越来越复杂。这种提示复杂度会削弱 LLM 函数调用能力。
- 定义多个函数。语音 AI 工作流通常需要五个或更多函数。
- 在一个会话中多次调用函数。
我们会大量测试所有主流 AI 模型发布,并频繁与训练这些模型的人交流。显然,以上所有属性都与训练当前一代 LLM 所用数据存在一定分布外差异。
这意味着,即使当前一代 LLM 在通用函数调用基准上表现良好,它们在语音 AI 用例上仍会遇到困难。不同 LLM 以及同一模型的不同更新,在函数调用上表现各异,并且在不同情境下对不同类型函数调用的表现也不同。
如果你在构建语音 AI 智能体,开发自己的 evals 来测试应用的函数调用性能很重要。见下文语音 AI Evals一节。
4.10.2 函数调用延迟¶
函数调用会增加延迟——可能增加很多——原因有四:
- 当 LLM 决定需要函数调用时,它会输出函数调用请求消息。你的代码随后针对请求的特定函数执行相应操作,再用相同上下文加上函数调用结果消息再次调用推理。因此,每次调用函数,都必须做两次推理调用,而不是一次。
- 函数调用请求不能流式处理。我们必须拿到完整函数调用请求消息,才能执行函数调用。
- 向提示中添加函数定义可能增加延迟。这有些模糊;最好开发专门面向延迟的 evals,测量向提示中添加函数定义带来的额外延迟。但可以明确的是,至少某些 API 在某些时候,只要启用了工具使用,无论是否实际调用函数,中位 TTFT 都会更高。
- 你的函数可能很慢!如果你在对接遗留后端系统,函数可能需要很长时间才返回。
每次用户说完话时,你都需要提供相当快的音频反馈。如果你知道函数调用可能需要很长时间返回,可能需要输出语音告知用户正在发生什么,并请他们等待。

包含函数调用的推理 TTFT。LLM TTFT 为 450ms,吞吐为每秒 100 tokens。如果函数调用请求 chunk 为 100 tokens,输出函数调用请求需要 1s。随后我们执行函数并再次运行推理。这一次可以流式输出,因此 450ms 后获得可用的首批 token。完整推理的 TTFT 为 1,450ms(不包括执行函数本身所需时间)。
你可以:
- 始终在执行函数调用前输出一条消息。“请稍等,我正在为你做 X……”
- 设置看门狗定时器,仅当函数调用循环在定时器触发前尚未完成时输出消息。“还在处理,请再稍等片刻……”
当然,也可以两者都做。执行长时间运行的函数调用时,还可以播放背景音乐35。
4.10.3 处理中断¶
LLM 被训练为期望函数调用请求消息和函数调用响应消息成对出现。
这意味着:
- 你需要停止语音到语音推理循环,直到所有函数调用完成。关于异步函数调用的说明见下文。
- 如果函数调用被中断且永远不会完成,你需要向上下文中放入一条表示……某种情况的函数调用响应消息。
这里的规则是:如果 LLM 调用了函数,你就需要向上下文中放入一对请求 / 响应消息。
- 如果你把悬空的函数调用请求消息放入上下文,然后继续多轮对话,就会创建一个偏离 LLM 训练方式的上下文。(有些 API 不允许这样。)
- 如果你完全不把请求 / 响应对放入上下文,就会通过上下文学习教 LLM 不要调用该函数36。 同样,结果不可预测,而且可能不是你想要的。
Pipecat 会在函数调用发起时向上下文插入一对请求 / 响应消息,从而帮助你遵循这些上下文管理规则。(当然,你可以覆盖此行为并直接管理函数调用上下文消息。)
下面展示了两种不同配置方式的函数调用模式:运行到完成和可中断。
初始上下文消息。函数调用请求消息和函数调用响应占位符:
User: Please look up the price of 1000 widgets.
LLM: Please wait while I look up the price for 1000 widgets.
function call request: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
function call response: { status: IN_PROGRESS }
函数调用完成时的上下文:
User: Please look up the price of 1000 widgets.
function call request: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
function call response: { result: { price: 12.35 } }
占位符允许函数调用运行期间对话继续,而不会“混淆”LLM:
User: Please look up the price of 1000 widgets.
LLM: Please wait while I look up the price for 1000 widgets.
function call request: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
function call response: { status: IN_PROGRESS }
User: Please lookup the price of 1000 pre-assembled modules.
LLM: Please wait while I also look up the price for 1000 pre-assembled modules.
function call request: { name: "price_lookup", args: { item: "pre_assembled_module", quantity: 1000 } }
function call response: { status: IN_PROGRESS }
如果函数调用被配置为可中断,那么当函数调用进行中用户说话时,它会被取消:
User: "Please look up the price of 1000 widgets."
LLM: "Please wait while I look up the price for 1000 widgets."
function call request: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
function call response: { status: CANCELLED }
User: Please lookup the price of 1000 pre-assembled modules.
LLM: Please wait while I look up the price for 1000 pre-assembled modules.
function call request: { name: "price_lookup", args: { item: "pre_assembled_module", quantity: 1000 } }
function call response: { status: IN_PROGRESS }
4.10.4 流式模式与函数调用 chunks¶
在语音 AI 智能体代码中,你几乎总是以流式模式执行对话推理调用。这让你尽可能快地获得前几个内容 chunks,这对语音到语音响应延迟很重要。
不过,流式模式和函数调用搭配起来有些别扭。流式处理对函数调用 chunks 没有帮助。你必须先组装出 LLM 的完整函数调用请求消息,才能调用函数37。
给推理提供商的一点反馈:随着 API 持续演进,请提供一种模式,能够原子化交付函数调用 chunks,并与任何流式内容 chunks 隔离。这会显著降低使用 LLM 提供商 API 的代码复杂性。
4.10.5 如何以及在哪里执行函数调用¶
当 LLM 发出函数调用请求时,你该怎么做?以下是一些常用模式:
- 直接在你的代码中执行与请求函数同名的函数调用。这是几乎所有 LLM 函数调用文档示例中看到的方式。
- 基于参数和上下文,把请求映射到某个操作。可以把它理解为让 LLM 做一个通用函数调用,然后由你的代码消歧。这种模式的优点是,如果给 LLM 的可选函数数量较少,它通常更擅长函数调用38。
- 把函数调用代理到客户端。这种模式适用于应用(非电话)场景。例如,想象一个 get_location() 函数。你想获取用户设备当前位置,因此需要接入该设备上的地理位置查询 API。
- 把函数调用代理到网络端点。这在企业场景中通常特别有用。定义一组与内部 API 交互的函数。然后在代码中创建一个抽象,把这些函数调用作为 HTTP 请求执行。

4.10.6 异步函数调用¶
有时你并不想从函数调用立即返回。你知道函数需要不可预测的长时间才能完成。也许它根本不会完成。也许你甚至希望启动一个长期运行的进程,随着时间以开放方式向上下文添加信息。
想象一个步行导览应用,允许用户表达对导览过程中可能看到事物的兴趣。“如果我们路过任何著名作家住过的地方,我特别想听听。” 一种不错的架构是,当用户表达特定兴趣时,LLM 调用一个函数。该函数启动后台进程,一旦发现与兴趣相关的信息,就把信息注入上下文。
今天,你无法直接使用 LLM 函数调用做到这一点。函数调用请求 / 响应消息必须成对出现在上下文中。
因此,不能定义如下形态的函数:
register_interest_generator(interest: string) -> Iterator[Message]
你需要做类似这样的事情:
create_interest_task_and_return_success_immediately (interest: string, context_queue_callback: Callable[Message]) -> Literal["in_progress", "canceled", "success", "failure"]
关于这个主题的更多讨论,见下文执行异步推理任务一节。
随着 LLM 和 API 演进以更好支持多模态对话用例,我们希望看到 LLM 研究者探索异步函数以及作为生成器的长期运行函数相关想法。
4.10.7 并行与组合函数调用¶
_并行函数调用_指 LLM 可以在单个推理响应中请求多个函数调用。_组合函数调用_指 LLM 可以灵活地连续调用多个函数,把函数链式组合起来执行复杂操作。
这些能力令人兴奋!
但它们也增加了语音智能体行为的可变性。这意味着你需要开发 evals 和监控,测试并行与组合函数调用是否在真实对话中按预期工作。
处理并行函数调用会让智能体代码更加复杂。除非有具体用途,否则我们经常建议禁用并行函数调用。
组合函数调用在工作良好时像魔法一样。我们最喜欢的早期组合函数调用一瞥,是看到 Claude Sonnet 3.5 把多个函数串联起来,根据文件名和时间戳从文件加载资源。
用户:Claude,加载我最近一张埃菲尔铁塔的照片。
函数调用请求:<list_files()>
函数调用响应:<['eiffel_tower_1735838843.jpg', 'empire_state_building_1736374013.jpg', 'eiffel_tower_1737814100.jpg', 'eiffel_tower_1737609270.jpg',
'burj_khalifa_1737348929.jpg']
函数调用请求:<load_resource('eiffel_tower_1737814100.jpg')>
函数调用响应:<{ 'success': 'Image loaded successfully', 'image': … }>
LLM:我已经加载了一张埃菲尔铁塔的图片。图片中,埃菲尔铁塔位于阴天之下。
LLM 会自己弄清如何把两个函数——list_files() 和 load_resource()——链式组合起来响应特定指令。这两个函数在 tools 列表中描述。但这种链式行为并未被提示词显式要求。
组合函数调用是 SOTA LLM 相对较新的能力。其表现“参差不齐”——惊人地好,但又令人沮丧地不一致。
4.11. 多模态¶
如今,LLM 除了文本之外,也能消费和生成音频、图像和视频。
前面我们讨论过 speech-to-speech 模型。这些模型能以音频作为输入,并以音频作为输出。
SOTA 模型的多模态能力正在快速进步。
GPT-4o、Gemini Flash 和 Claude Sonnet 都有非常好的视觉能力——它们都接受图像输入。这些模型的视觉支持最初聚焦于描述图像内容和转录图像中出现的文本。每次发布能力都会扩展。计数物体、识别边界框,以及更好理解图像中物体之间关系,都是较新版本中可用的有用能力。
Gemini Flash 可以对视频输入进行推理,包括同时理解视频和音轨39。
一类有趣的新语音应用是可以“看见”你的屏幕,并帮助你在本地机器或 Web 浏览器上执行任务的助手。已经有不少人构建了语音驱动 Web 浏览的脚手架。
我们认识的一些程序员如今说话和打字一样多。把语音输入接入 Cursor 或 Windsurf 相当容易40。 也可以接入屏幕捕获,让 AI 编程助手看到你看到的一切——编辑器中的代码、正在构建的 Web 应用 UI 状态、终端中的 Python stacktrace。这种完全多模态 AI 编程助手,感觉像是本文中我们反复提到的另一种未来一瞥41。
目前,所有 SOTA 模型都以不同组合支持多模态。
- GPT-4o (gpt-4o-2024-08-06) 支持文本和图像输入,文本输出。
- gpt-4o-audio-preview 支持文本和音频输入,文本和音频输出。(不支持图像输入。)
- Gemini Flash 支持文本、音频、图像和视频输入,但只支持文本输出。
- OpenAI 新的语音转文本和文本转语音模型完全可控制,并构建在 gpt-4o 基础之上,但专门用于文本和音频之间转换:gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-mini-tts。
多模态支持正在快速演进,我们预计上面列表很快会过时!
对语音 AI 来说,多模态最大的挑战是音频和图像会使用大量 token,而更多 token 意味着更高延迟。
| 示例媒体 | 近似 token 数 |
|---|---|
| 一分钟语音音频转为文本 | 150 |
| 一分钟语音音频作为音频 | 2,000 |
| 一张图像 | 250 |
| 一分钟视频 | 15,000 |
对某些应用来说,一个巨大工程挑战是:在处理大量图像的同时实现对话式延迟。对话式延迟要求保持较小上下文,或依赖厂商特定缓存 API。图像会给上下文增加很多 token。
想象一个个人助理智能体,它一直在你的电脑上运行,并把观看屏幕作为工作循环的一部分。你可能希望能问:“一个小时前我正准备读一条 tweet,结果接了那个电话,然后忘了这事并关掉了标签页。那条 tweet 是什么?”
一小时前相当于近一百万 token。 即使你的模型可以容纳一百万 token 的上下文42,每轮用这么多 token 做多轮对话的成本和延迟也高得无法接受。
你可以把视频总结为文本,并只把摘要保留在上下文中。你可以计算 embeddings 并做类似 RAG 的查找。LLM 非常擅长特征总结,也很擅长使用函数调用触发复杂 RAG 查询。但这两种方法工程实现都很复杂。
最终,最大的杠杆是上下文缓存。所有 SOTA API 提供商都提供某种缓存支持。今天的缓存功能对语音 AI 用例而言还都不完美。随着训练 SOTA 模型的人更加关注多模态、多轮对话用例,我们预计今年缓存 API 会改进。
5. 使用多个 AI 模型¶
今天的生产级语音 AI 智能体会组合使用多个深度学习模型43。
如前所述,典型语音 AI 处理循环用语音转文本模型转录用户声音,把转录文本传给 LLM 生成响应,然后执行文本转语音步骤生成智能体语音输出。
此外,今天许多生产级语音智能体会以复杂且多样的方式使用多个模型。
5.1. 使用多个微调模型¶
多数语音 AI 智能体使用 OpenAI 或 Google(有时也包括 Anthropic 或 Meta)的 SOTA44 模型。使用最新、表现最好的模型很重要,因为语音 AI 工作流通常正处在模型能力的 锯齿状前沿 45边缘。语音智能体需要能遵循复杂指令,以自然方式参与与人的开放对话,并可靠使用函数和工具。
但对于一些专门用例,为对话不同状态微调模型是有意义的。微调模型可以比大模型更小、更快、更便宜,同时仍在特定任务上表现同样好(或更好)。
想象一个帮助用户从大型工业供应目录中订购零件的智能体。针对这个任务,你可能训练多个不同模型,每个模型专注于不同类别:塑料材料、金属材料、紧固件、管道、电气、安全设备等。
微调模型通常可以在两个重要类别中“学习”东西:
- 嵌入知识——模型可以学习事实。
- 响应模式——模型可以学习以特定方式转换数据,这也包括学习对话模式和流程。
我们假想的工业供应公司拥有大量原始数据:
- 一个非常大的知识库,包括数据表、制造商建议、价格,以及目录中每个零件的内部数据。
- 与真人支持代理的文本聊天记录、邮件链和电话转录。

把这些原始数据转换为用于微调模型的数据集是一项很大的工作,但可处理。所需的数据清洗、数据集创建、模型训练和模型评估都是被充分理解的问题。
一个重要提醒:不要直接跳到微调——先从提示工程开始。
提示几乎总能达到与微调相同的任务结果。微调的优势在于能够使用更小模型,这可以转化为更快推理和更低成本46。
使用提示,你可以比微调更容易起步,也能更快迭代47。
在初步探索如何为不同对话状态使用不同模型时,可以把提示词看作微型“模型”。你通过精心构造一个大的、特定上下文提示词来教 LLM 做什么。
- 对嵌入知识,实现一个搜索能力,可以从知识库拉取信息,并把搜索结果组装成有效提示。关于这一点,见下文 RAG 与记忆一节。
- 对响应模式,嵌入你期望模型如何回答不同问题的示例。有时只需少数示例就够。有时你需要很多示例——100 个或更多。
5.2. 执行异步推理任务¶
有时你希望使用 LLM 执行一个需要相对较长时间运行的任务。记住,在核心对话循环中,我们的目标响应时间约为一秒(或更短)。如果某个任务需要超过几秒钟,你有两个选择:
- 告诉用户正在发生什么,并请他们等待。请稍等,我帮你查一下……”
- 异步执行较长任务,让对话在后台任务进行时继续。“我会帮你查一下。在此期间,你还有其他问题吗?”
如果你异步执行推理任务,可能会选择为这个特定任务使用不同 LLM。(因为它与核心对话循环解耦。)你可以使用一个对语音响应来说太慢的 LLM,或者一个为特定任务微调过的 LLM。
异步推理任务的一些示例:
- 实现内容“护栏”。(见内容护栏一节。)
- 创建图像。
- 生成在沙箱中运行的代码。
推理模型48近期的惊人进展扩展了我们能要求 LLM 做的事情。不过,你不能把这些模型用于语音 AI 对话循环,因为它们通常会花大量时间生成 thinking tokens,之后才发出可用输出。但把推理模型作为多模型语音 AI 架构中的异步部分使用,可以工作得很好。
异步推理通常由 LLM 函数调用触发。一个简单方法是定义两个函数。
perform_async_inference()—— 当 LLM 决定应运行任何长时间推理任务时调用它。你可以定义多个这样的函数。注意,你需要启动异步任务,然后立即返回基本的_任务已成功启动_响应,以便函数调用请求和响应消息在上下文中正确排序49。queue_async_context_insertion()—— 当异步推理完成时,由你的编排层调用它。棘手之处在于,如何把结果插入上下文取决于你想做什么,以及你使用的 LLM / API 允许什么。一种方法是等到任何正在进行的对话轮次结束(包括所有函数调用完成),把异步推理结果放入一条特别构造的用户消息,然后再运行一轮对话。
5.3. 内容护栏¶
语音 AI 智能体有几类漏洞,会给某些用例造成重大问题。
- 提示注入
- 幻觉
- 过期知识
- 生成不当或不安全内容
_内容护栏_是试图检测这些问题的代码的通用术语——既保护 LLM 免受意外和恶意提示注入,也在坏的 LLM 输出发送给用户前捕获它。
使用特定模型(或多个模型)做护栏有几个潜在优势:
- 小模型可能很适合护栏和安全监控。识别问题内容可以是相对专门的任务。(事实上,对于提示注入缓解而言,你并不一定想要一个能以完全通用方式被提示的模型。)
- 使用不同模型做护栏工作的优势是,它不会与你的主模型有完全相同的弱点。至少理论上如此。
几个开源智能体框架包含护栏组件。
- llama-guard 是 Meta llama-stack 的一部分
-
NeMO Guardrails 是一个开源工具包,用于为基于 LLM 的对话应用添加可编程护栏

NVIDIA NeMo Guardrails 框架支持的五类护栏。图来自 NeMo Guardrails 文档
这两个框架都是面向文本聊天设计的,而不是语音 AI。但两者都有有用的想法和抽象,如果你在思考护栏、安全和内容审核,值得看看。
值得注意的是,LLM 在避免所有这些问题方面,已经比一年前好得多得多。
总体而言,使用大型实验室最新模型时,幻觉已不再是主要问题。如今我们经常看到的幻觉只有两类。
- LLM “假装”调用函数,但实际上没有调用。这可以通过提示修复。你需要好的 evals 来确认你的提示下没有这种情况。当你在 evals 中看到函数调用幻觉时,迭代提示,直到不再看到它。(记住,多轮对话会_真正_考验 LLM 函数调用能力,因此 evals 需要镜像真实世界的多轮对话。)
- 当你期望 LLM 做 Web 搜索时,它却产生幻觉。内置搜索 grounding 是 LLM API 相对较新的功能。LLM 是否会选择执行搜索仍有些不可预测。如果它们不搜索,可能会用权重中嵌入的(较旧)知识回答,或产生幻觉。与函数调用幻觉不同,这并不特别容易通过提示修复。但很容易知道搜索是否实际执行。因此,你可以在应用 UI 中显示该信息,或把它注入语音对话。如果你的应用依赖 Web 搜索,这样做是好主意。你把理解和处理问题的责任推给用户,但这比向用户隐藏“搜索了”或“没搜索”的区别要好。积极的一面是,当搜索 grounding 工作正常时,它基本可以消除过期知识问题。
各大实验室的 API 都有非常好的内容安全过滤器。
提示注入缓解也比一年前好得多,但随着 LLM 获得新能力,潜在提示注入攻击的表面积也在扩大。例如,来自图像中文本的提示注入现在是一个问题。
作为非常非常通用的指导原则:今天在语音 AI 用例中,由正常用户行为导致的意外提示注入并不常见。但仅通过用户输入来引导 LLM 行为、从而颠覆系统指令,确实是可能的。测试智能体时需要牢记这一点。尤其重要的是,要对任何访问后端系统的函数的 LLM 生成输入进行清洗和交叉校验。
5.4. 执行单次推理动作¶
对 AI 工程师来说,学习如何利用 LLM 是一个持续过程。这个过程的一部分,是我们如何思考这些新工具的心智转变。刚开始使用 LLM 时,多数人会通过“语言模型独特擅长什么?”这个视角看它们。但 LLM 是通用工具。它们擅长非常广泛的信息处理任务。
在语音智能体语境中,我们总会有一条执行 LLM 推理的代码路径。我们不必把 LLM 限制为只用于核心对话循环。
例如:
- 任何时候你想使用正则表达式,可能都可以写一个提示词替代。
- 对 LLM 输出进行后处理通常很有用。例如,你可能希望以两种格式生成输出:用于 UI 显示的文本,以及用于交互对话的语音。你可以提示对话 LLM 生成格式良好的 markdown 文本,然后再次提示 LLM 把文本缩短并重新格式化用于语音生成50。
- 递归很强大51。 你可以让 LLM 生成一个列表,然后再次调用 LLM 对列表中每个元素执行操作。
- 事实证明,你经常会想总结多轮对话。LLM 是非常出色且可控制的摘要器。关于这一点,见下文脚本化与指令遵循一节。
许多这些新兴代码模式看起来像是语言模型把自己或另一个语言模型当作工具使用。
这是一个非常强大的想法,我们预计 2025 年会有很多人研究它。智能体框架可以把对此的支持内置到库级 API 中。模型也可以被训练为以递归方式执行推理,大致类似于训练它们调用函数和执行代码。
5.5. 走向自我改进系统¶
当我们通过 API 访问一个 SOTA“模型”时,访问的并不是单一 artifact。API 背后的系统使用多种路由、多阶段处理和分布式系统技术,以快速、灵活、可靠且超大规模的方式执行推理。这些系统一直在被调整。权重会更新。低层推理实现一直在变得更高效。系统架构会演进。
大型实验室正在持续缩短用户如何使用其 API 与它们如何实现推理和其他能力之间的反馈循环。
这些越来越快的反馈循环,是如今惊人宏观 AI 进展的重要组成部分。
受此启发,我们智能体级代码中的微观反馈循环可以是什么样?能否构建特定脚手架,在对话过程中提升智能体表现?
- 监控智能体在用户说完前打断用户的频率,并动态调整 VAD 超时等参数。
- 监控用户打断智能体的频率,并动态调整 LLM 响应长度。
- 寻找表明用户难以理解对话的模式——也许用户不是母语者。调整对话风格,或主动提出切换语言。
你还能想到其他想法吗?
LLM 在多轮会话中基于用户反馈调整行为的示例(上下文学习):
用户:MNI 最近表现怎么样?
智能体:Miami Dolphins 昨天以 21 比 3 赢下比赛,
现在领跑 AFC East,常规赛还剩两场。
用户:不,我说的是股票 MNI。
智能体:啊,抱歉!你问的是 MNI 这只股票的表现,
它是 McClatchy Company 的股票代码……
从这一刻起,模型会更倾向于把音素或转录文本理解为“MNI”,
而不是“Miami”。
6. 脚本化与指令遵循¶
一年前,仅仅能够构建以自然人类延迟进行开放对话的语音智能体,就已经令人兴奋。
现在,我们正在部署语音 AI 智能体来完成复杂的真实世界任务。对今天的用例而言,我们需要指示 LLM 在一个会话中专注于特定目标。很多时候,我们需要 LLM 按特定顺序执行子任务。
例如,在医疗患者 intake 工作流中,我们希望智能体:
- 在做任何其他事情之前验证患者身份。
- 确保询问患者当前正在服用哪些药物。
- 如果患者说正在服用药物 X,则询问特定追问。
- 等等……
我们把构造逐步工作流称为_脚本化_。过去一年语音 AI 开发的一条经验是,仅靠_提示工程_很难实现脚本可靠性。
单个提示中能塞入的细节有限。相关地,随着多轮对话中上下文增长,LLM 需要跟踪的信息越来越多,指令遵循准确率会下降。
许多语音 AI 开发者正在转向状态机方法来构建复杂工作流。与其编写一条很长、很详细的系统指令来引导 LLM,不如定义一系列状态。每个状态包括:
- 一个系统指令和工具列表。
- 一个对话上下文。
- 一个或多个从当前状态到另一个状态的出口。
每次状态转换都是一个机会,可以:
- 更新系统指令和工具列表。
- 总结或修改上下文52。
状态机方法效果很好,因为更短、更聚焦的系统指令、工具列表和上下文,会显著改善 LLM 指令遵循。
挑战在于找到正确平衡:一方面利用 LLM 进行开放自然对话的能力,另一方面确保 LLM 可靠执行待完成工作中的关键部分。
Pipecat Flows 是构建在 Pipecat 之上的库,帮助开发者创建工作流状态机。
状态图以 JSON 表示,并可以加载到 Pipecat 进程中。还有一个用于创建这些 JSON 状态图的图形编辑器。
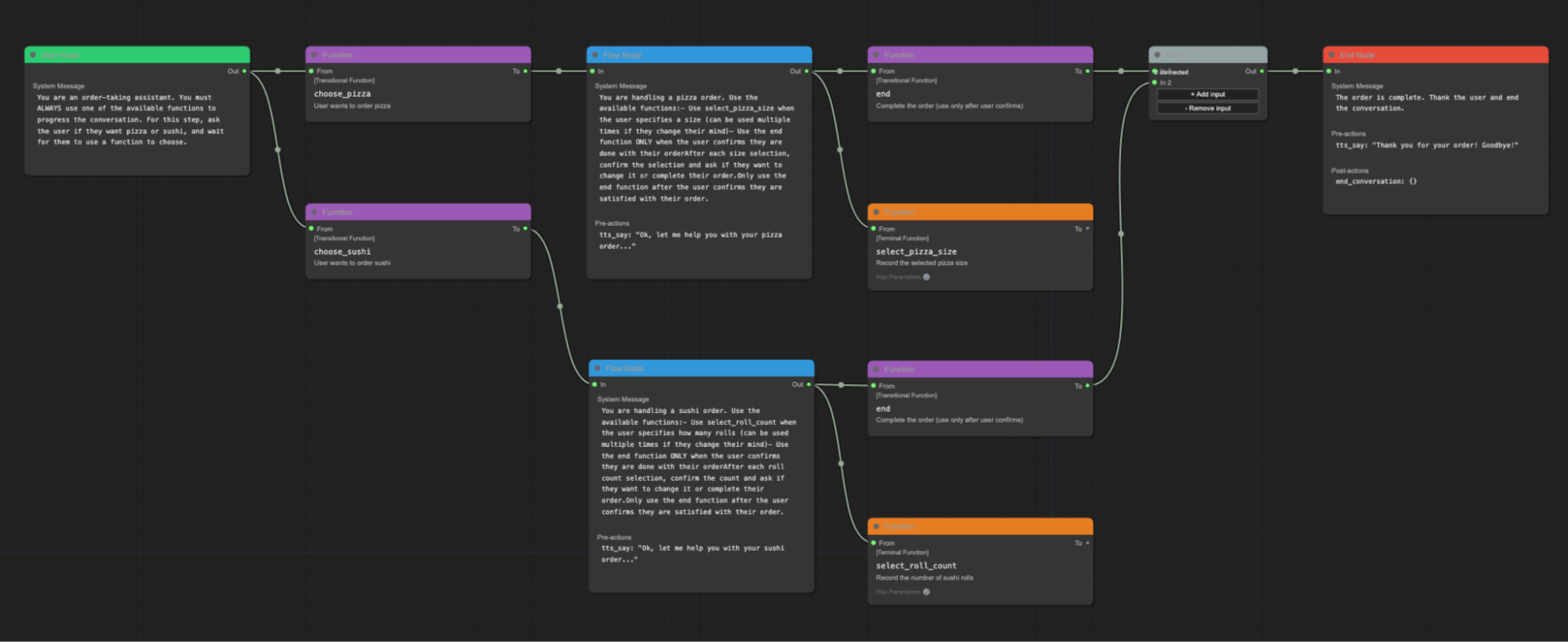
Pipecat Flows 和状态机目前正在获得大量开发者采用。但对于复杂工作流抽象的构建,还有其他有趣思路。
AI 研发的一个活跃领域是多智能体系统。你可以把工作流看作多智能体系统,而不是一系列要遍历的状态。
Pipecat 的核心架构组件之一是并行 pipeline。并行 pipeline 允许你拆分经过处理图的数据,并对其操作两次(或更多)。你可以阻塞和过滤数据。你可以定义许多并行 pipeline。你也可以把工作流看作一组带 gate、协调运行的并行 pipelines。
语音 AI 工具的快速演进令人兴奋,也凸显了我们仍处在弄清如何构建这类新程序的早期阶段。
7. 语音 AI Evals¶
一种非常重要的工具是 eval,即 evaluation(评估)的缩写。
Eval 是机器学习术语,指评估系统能力并判断其质量的工具或流程。
7.1. 语音 AI evals 不同于软件单元测试¶
如果你来自传统软件工程背景,你习惯于把测试看作(大多)确定性的练习。
语音 AI 需要不同于传统软件工程的测试。语音 AI 输出是非确定性的。测试语音 AI 的输入是复杂、分支、多轮的对话。
你不再是测试某个特定输入会产生某个特定输出 (f(x) = y),而需要运行概率性 evals——大量测试运行,观察某类事件发生的频率53。对某些测试,某类情况 8/10 次正确可以接受;对另一些测试,准确率需要达到 9.99/10。
你也不再只有一个输入,而是有很多输入:所有用户响应。这使得如果不尝试模拟用户行为,就很难测试语音 AI 应用。
最后,语音 AI 测试的结果不是二元的,很少会像传统单元测试那样给出明确的通过或失败。相反,你需要审查结果并决定权衡。
7.2. 失败模式¶
语音 AI 应用有特定形态和失败模式,会影响我们如何设计和运行 evals。延迟至关重要(因此文本模式系统可接受的延迟,对语音系统来说可能就是失败)。它们是多模型系统(例如,性能不佳可能由 TTS 不稳定而不是 LLM 行为导致)。
今天经常带来挑战的领域包括:
- 首次发声时间和智能体响应时间的延迟
- 转录错误
- 理解和口头表达地址、邮箱、姓名、电话号码
- 中断
7.3. 制定 eval 策略¶
一个初级 eval 流程可以简单到只是一张包含提示和测试用例的电子表格。
一种典型方法是:每次测试新模型或改变系统的主要部分时,运行每个提示,并使用 LLM 判断响应是否落在某种预期参数定义内。
拥有基础 eval 远好于完全没有 eval。但随着开始规模化运行,投资 evals——拥有真正好的 evals——会变得关键。
为语音 AI 用例提供复杂工具的评估平台刚刚开始出现。三个较早投入音频 evals 特定工作流和工具的平台是 Coval、FreePlay 和 Weights & Biases Weave。三者都有不错的 Pipecat 集成。
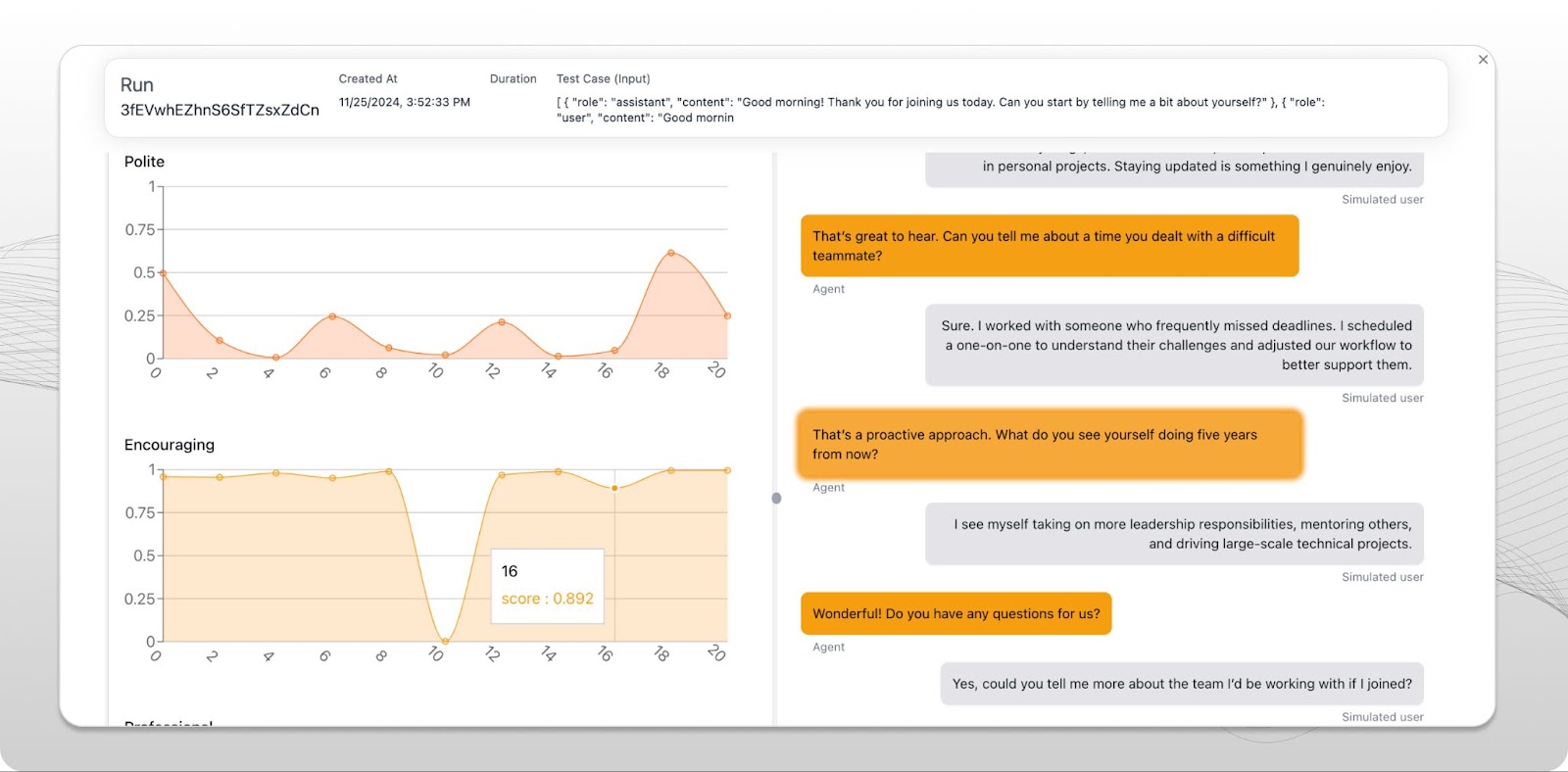
这些平台可以帮助:
- 提示迭代。
- 音频、工作流、函数调用和对话语义评估的现成指标。
- 在问题区域 hillclimbing(例如,让智能体更擅长处理中断)。
- 回归测试(确保修复一个问题区域时,不会在其他此前已解决的问题区域引入回归)。
- 跟踪性能随时间变化,包括开发者所做更改,以及不同用户群体之间的变化。
8. 与电话基础设施集成¶
今天增长最快的语音 AI 用例大多涉及电话呼叫。 AI 语音智能体正在大规模接听和拨打电话。
其中一部分发生在传统呼叫中心。呼叫中心主要把语音 AI 视为一种可以提高“deflection rates(分流率)”的技术——即由自动化而非人工坐席处理的呼叫比例。这使采用语音 AI 的 ROI 很清晰。如果 LLM 每分钟成本低于人工坐席每分钟成本,购买决策就很简单54。
不过,除了简单 ROI 计算之外,还有一些有趣事情在加速采用。
语音 AI 智能体的可扩展性是人工团队不具备的。一旦部署语音 AI,高峰期等待时间会下降。(客户满意度评分会直接上升。)
而且 LLM 有时能比人工坐席做得更好,因为我们给了它们更好的工具。在许多客户支持情境中,人工坐席必须处理多个遗留后端系统。及时找到信息可能很有挑战。当我们把语音 AI 部署到同样情境中时,必须构建对这些遗留系统的 API 级访问。新的 LLM-plus-API 层正在推动向语音 AI 的技术转型。
显然,生成式 AI 将在未来几年彻底重塑呼叫中心格局。
在呼叫中心之外,语音 AI 正在改变小企业接听电话的方式,以及它们如何使用电话进行信息发现和协调。我们每天都与正在为你听过的每个业务垂直领域构建专用 AI 电话解决方案的初创公司交流。
这个领域的人经常开玩笑说,不久之后人类根本不会拨打或接听电话。电话都会是 AI-to-AI。根据我们看到的趋势线,这里面确实有几分真实!
如果你对语音 AI 的电话集成感兴趣,有几个缩写和常见概念需要熟悉。
- PSTN 是_public, switched, telephone network_(公共交换电话网络)。如果你需要与带电话号码的真实电话交互,就需要使用 PSTN 平台。Twilio 是几乎每个开发者都听说过的 PSTN 平台。
- SIP 是 IP 电话使用的一种特定协议,但一般意义上,SIP 也用来指系统之间的电话互联。例如,如果你对接呼叫中心技术栈,就需要使用 SIP。你可以使用 SIP 提供商,也可以托管自己的 SIP 服务器。
- DTMF 音是用于导航电话菜单的按键声音。语音智能体需要能够发送 DTMF 音,才能与真实电话系统交互。LLM 很擅长处理电话菜单。你只需要做一点提示工程,并定义发送 DTMF 音的函数。
- 语音智能体经常需要执行呼叫转接。在简单转接中,语音 AI 通过调用触发呼叫转接的函数退出会话55。 warm transfer 是从一个坐席到另一个坐席的交接,其中坐席在把来电者转给第二个坐席前会彼此交谈。语音 AI 智能体也能像人类一样做 warm transfer。语音智能体一开始与人类来电者交谈,然后把人类来电者置于保持状态,与被接入电话的新人工坐席交谈,最后把人类来电者连接给人工坐席。
9. RAG 与记忆¶
语音 AI 智能体经常访问外部系统中的信息。例如,你可能需要:
- 把用户相关信息纳入 LLM 系统指令。
- 检索先前对话历史。
- 在知识库中查找信息。
- 执行 Web 搜索。
- 做实时库存或订单状态检查。
所有这些都属于 RAG——检索增强生成(retrieval augmented generation)。RAG 是结合信息检索和 LLM 提示的通用 AI 工程术语。
语音智能体“最简单可能的 RAG”是在对话开始前查找用户信息,然后把这些信息合并到 LLM 系统指令中。
简单 RAG——在会话开始时执行查找:
user_info = fetch_user_info(user_id)
system_prompt_base = "You are a voice AI assistant..."
system_prompt = (
system_prompt_base
+ f"""
The name of the patient is {user_info["name"]}.
The patient is {user_info["age"]} years old.
The patient has the following medical history: {user_info["summarized_history"]}.
"""
)
RAG 是一个很深的主题,也在快速变化56。 技术范围从上面这种相对简单、只使用基础查找和字符串插值的方法,到使用 embeddings 和向量数据库组织大量半结构化数据的系统。
很多时候,80/20 方法就能带你走很远。如果你有既有知识库,就使用你已有的 API。编写简单 evals,这样可以测试几种把查找结果注入对话上下文的不同格式。部署到生产,然后监控它在真实用户中的效果。
async def query_order_system(function_name, tool_call_id, args, llm, context, result_callback):
"First push a speech frame. This is handy when the LLM response might take a while."
await llm.push_frame(TTSSpeakFrame("Please hold on while I look that order up for you."))
query_result = order_system.get(args["query"])
await result_callback({
"info": json.dumps({
"lookup_success": True,
"order_status": query_result["order_status"],
"delivery_date": query_result["delivery_date"],
})
})
llm.register_function("query_order_system", query_order_system)
会话中的 RAG。当需要信息查找时,定义一个函数供 LLM 调用。在这个例子中,我们还发出一段预设语音短语,让用户知道系统需要几秒钟才能响应。
一如既往,语音 AI 面临的延迟挑战比非语音 AI 系统更大。当 LLM 发出函数调用请求时,额外推理调用会增加延迟。查找外部系统中的信息也可能很慢。在执行 RAG 查找前触发一个简单语音输出,让用户知道工作正在进行,通常很有用。
更广义地说,跨会话记忆是一种有用能力。想象一个语音 AI 个人助理,需要记住你谈过的一切。两种通用方法是:
- 把每次对话保存到持久化存储中。测试几种把对话加载到上下文中的方法。例如,对个人助理用例很有效的一种策略是:智能体启动时始终完整加载最近一次对话,加载最近 N 次对话的摘要,并定义一个查找函数,让 LLM 能在需要时动态加载更早的对话。
- 把对话历史中的每条消息连同消息图元数据一起分别保存到数据库中。索引每条消息(也许使用语义 embeddings)。这允许你动态构建分支对话历史。如果你的应用大量使用图像输入(LLM vision),你可能希望这么做。图像会占用大量上下文空间!57 这种方法也允许你构建分支 UI,这是 AI 应用设计者刚开始探索的方向。
语音 AI 应用通常有一些传统应用组件——Web app 前端、API 端点和其他后端元素。但智能体进程本身与传统应用组件有足够差异,因此部署和扩展语音 AI 会带来独特挑战。
10. 托管与扩展¶
10.1 架构¶
- 语音 AI 智能体对话循环通常是一个长期运行的进程(不是生成单个响应后退出的请求 / 响应函数)。
- 语音智能体实时流式传输音频。任何导致流式传输停顿的因素都可能产生音频毛刺。(共享虚拟机上的 CPU 峰值、阻塞音频线程执行哪怕 10ms 的程序流等。)
- 语音智能体通常需要 WebSocket 或 WebRTC 连接。云服务网络网关和路由产品对 WebSockets 的支持远不如 HTTP。它们通常完全不支持 UDP。(WebRTC 需要 UDP。)
由于所有这些原因,通常不可能使用 AWS Lambda 或 Google Cloud Run 这类 serverless 框架做语音 AI。
今天部署语音 AI 智能体的最佳实践是:
- 一旦越过原型阶段,就投入工程时间创建轻量工具,用于构建部署智能体的 Docker(或类似)容器。
- 把容器推送到你选择的计算平台。对简单部署,可以保持固定数量虚拟机运行。不过到某个阶段,你会希望接入平台工具,以便自动扩缩容、优雅部署新版本、实现良好服务发现和故障转移,以及构建其他规模化 devops 需求。
- Kubernetes 是如今管理容器、部署和扩展的标准。Kubernetes 学习曲线陡峭,但所有主要云平台都支持它。Kubernetes 周围也有非常庞大的生态系统。
- 对软件更新,你会希望设置较长 drain time,让现有连接一直保持到会话结束。在 Kubernetes 中这并不特别难,但细节取决于你的 k8s 引擎和版本。
- 冷启动对语音 AI 智能体是个问题,因为快速连接时间很重要。保持一个空闲智能体池是避免长冷启动最简单的方法。如果你的工作负载不要求本地运行大模型,通常可以不费太多力气就工程化实现快速容器冷启动58。
首次部署到生产环境时,虚拟机规格和容器装箱经常让人踩坑。智能体所需规格会因你使用的库以及在智能体进程内做多少 CPU 密集工作而异。一个不错的经验法则是,从每个虚拟机 CPU 运行一个智能体开始,并配置为你在开发机器上看到的智能体进程最大 RAM 消耗的两倍59。
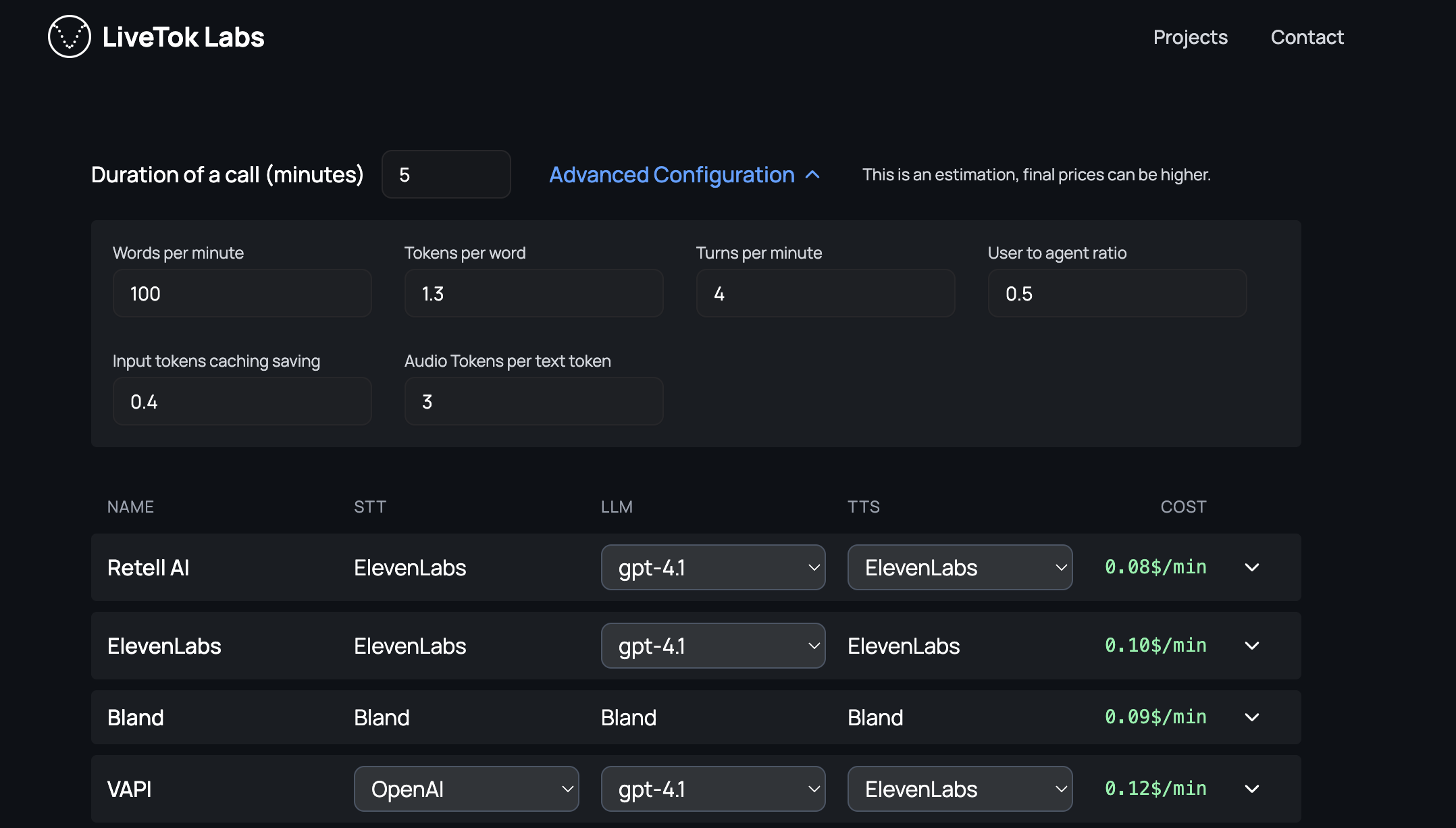
10.2 计算每分钟成本¶
语音 AI 成本因使用的模型、API 和托管基础设施而差异很大。成本也取决于用例。例如,如上文成本比较所述,较长会话的每分钟成本通常更高。电话也比 WebRTC 传输更昂贵。
如果使用 OpenAI Realtime API 这类 speech-to-speech API,成本可能达到每分钟 $0.20 或更高;包含全套能力的托管智能体平台约为每分钟 $0.10;而在大规模下高度成本优化的部署可低至每分钟 $0.02。
我们有时看到人们犯的一个错误是,在计算语音和 LLM API 成本之前,就先优化智能体托管本身的成本。一般来说,智能体进程自身的云运行成本不到总每分钟成本的 1%。 几乎永远不值得花工程精力优化每 vCPU 智能体并发。
这里有一个交互式成本计算器,由 Gustavo Garcia 开发。
或者,如果你更喜欢电子表格,这里有一张电子表格,你可以复制并用作计算每分钟成本的起点。
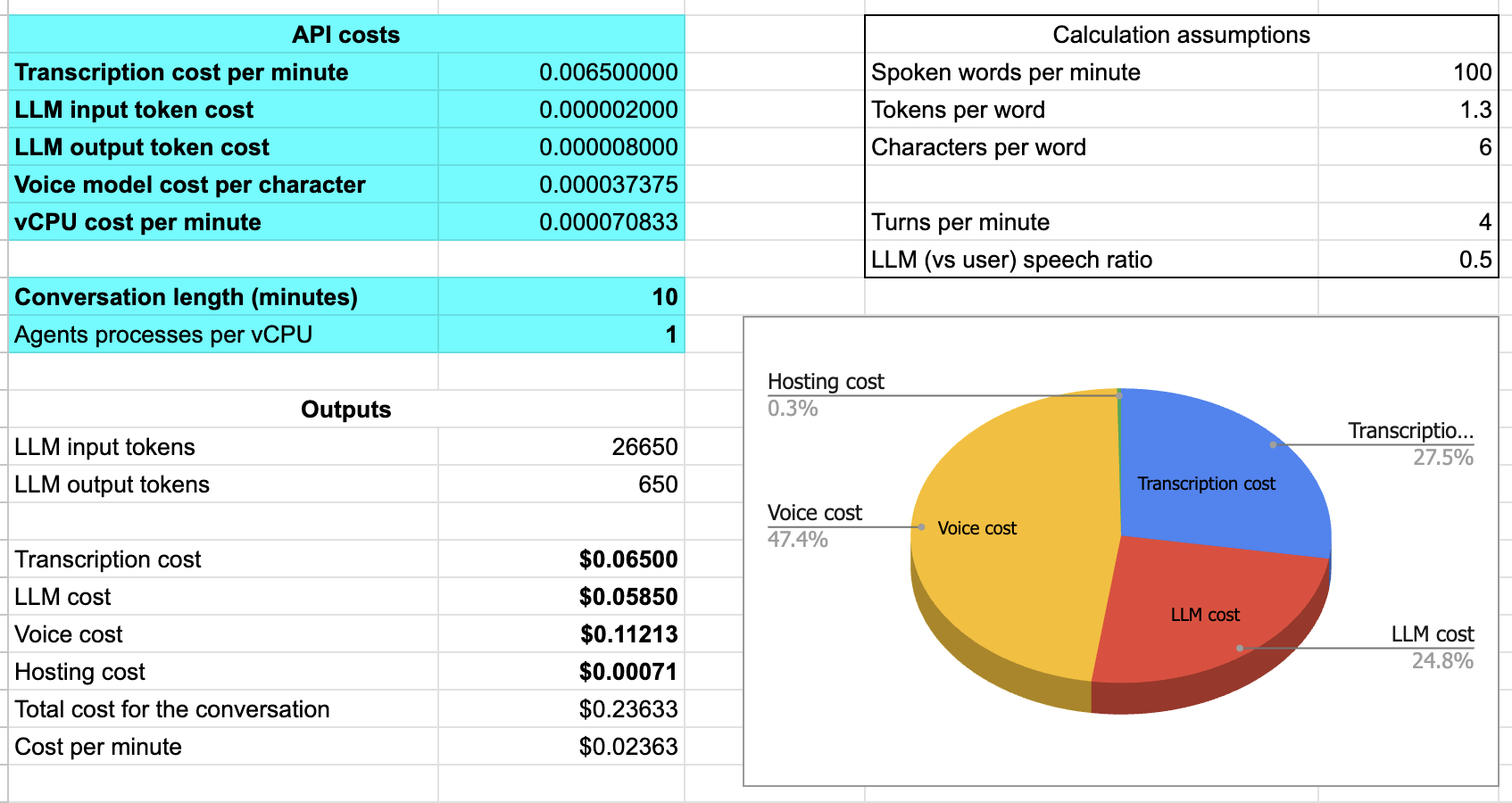
电子表格截图中的数字针对一个使用 Deepgram、GPT-4o 和 Cartesia 的自托管智能体。对于十分钟会话,每分钟成本约为两分半美分。转录和 LLM 推理各占约四分之一成本。语音生成约占一半成本。托管不到 1%。
当然,这不是自托管实际成本的现实图景。如果你构建和维护所有自己的托管基础设施,除了智能体本身之外,还需要设置、扩展和维护许多系统与能力。
- 服务发现
- 负载均衡
- 日志
- 监控
- 带宽
- 多区域
- 安全
- 合规与监管功能(例如数据驻留)
- 分析
- 客户支持
11. 2025 年会发生什么¶
说到 AI 工程的增长,语音 AI 在 2024 年增长巨大,我们预计 2025 年会继续如此。
不断扩大的兴趣和采用,会在一些重要核心领域推动持续进展:
- 所有模型构建者和服务提供商都会做更多延迟优化。很长时间里,多数实现服务的人和几乎所有公开基准都关注吞吐而不是延迟。对语音 AI 来说,我们关心首个 token 时间远多于每秒 tokens 数。
- 朝着在模型和 API 中完全集成所有非文本模态继续进展。
- 测试和 eval 工具中出现更多音频特定功能。
- 支持实时多模态用例需求的上下文缓存 API。
- 多个提供商推出新的语音智能体平台。
- 多个提供商推出 speech-to-speech 模型 API。
- 能够结合上下文来提升转录准确率和语音生成质量的上下文化语音模型。
如果你对四位语音 AI 领域专家关于 2025 年的 hot takes 感兴趣,可以跳到 1 月旧金山 Voice AI Meetup panel 录音的 54:05。Karan Goel、Niamh Gavin、Shrestha Basu-Mallick 和 Swyx 都给出了他们对来年趋势的预测:通用记忆、Hollywood 中的 AI、从模型模仿走向模型理解,以及对机器人技术的逆向观点。
这将是有趣的一年。
贡献者¶
主要作者¶
Kwindla Hultman Kramer
感谢 Brooke Hopkins 对 evals 章节的帮助,Zach Koch 对 Llama 性能和 Ultravox 的见解,以及 Brendan Iribe 关于转向上下文化语音模型重要性的说明。
贡献作者60¶
aconchillo, markbackman, filipi87, Moishe, kwindla, kompfner, Vaibhav159, chadbailey59, jptaylor, vipyne, Allenmylath, TomTom101, adriancowham, imsakg, DominicStewart, marcus-daily, LewisWolfgang, mattieruth, golbin, adithyaxx, jamsea, vr000m, joachimchauvet, sahilsuman933, adnansiddiquei, sharvil, deshraj, balalofernandez, MaCaki, TheCodingLand, milo157, RJSkorski, nicougou, AngeloGiacco, kylegani, kunal-cai, lazeratops, EyrisCrafts, roey-priel, aashsach, jcbjoe, Dev-Khant, wg-daniel, cbrianhill, ankykong, nulyang, flixoflax, DANIIL0579, Antonyesk601, rahultayal22, lucasrothman, CarlKho-Minerva, 0xPatryk, pvilchez, pedro-a-n-moreira, RonakAgarwalVani, xtreme-sameer-vohra, shaiyon, soof-golan, yashn35, zboyles, balaji-atoa, eddieoz, mercuryyy, rahulunair, porcelaincode, weedge, wtlow003, zzz-heygen, adidoit, ArmanJR, Bnowako, chhao01, Regaddi, cyrilS-dev, DamienDeepgram, danthegoodman1, dleybz, ecdeng, gregschwartz, KevGTL, louisjoecodes, M1ngXU, mattmatters, MoofSoup, natestraub
设计¶
Sascha Mombartz
Akhil K G
-
这里我们指的是广义含义,而不是某些 LLM 的“structured output”功能这一狭义含义。 ↩
-
我们最初为 2025 年 2 月的 AI Engineering Summit 撰写了本指南。我们在 2025 年 5 月中旬对其进行了更新。 ↩
-
webrtcforthecurious.com —— WebRTC 与语音 AI 相关,后文 WebSockets 与 WebRTC一节会讨论。 ↩
-
Pipecat 集成了 60 多种 AI 模型和服务,并提供轮次检测和中断处理等能力的 SOTA 实现。你可以使用 Pipecat 编写通过 WebSockets、WebRTC、HTTP 和电话与用户通信的代码。Pipecat 包含面向多种基础设施平台的传输实现,包括 Twilio、Telnyx、LiveKit、Daily 等。还有面向 JavaScript、React、iOS、Android 和 C++ 的客户端 Pipecat SDK。 ↩
-
例如,用于检测常见 LLM 错误和安全问题。 ↩
-
Let's delve —— 编者注。 ↩
-
例如 CRM、专有知识库和呼叫中心系统。 ↩
-
通过提示让模型做特定事情有多容易? ↩
-
语音 AI 智能体高度依赖函数调用。 ↩
-
如果你计划为自己的用例微调 LLM,Llama 3.3 70B 是一个非常好的起点。下面会进一步讨论微调。 ↩
-
音频模型的这个延迟问题显然可以通过缓存、巧妙 API 设计,以及模型自身架构演进的组合来解决。 ↩
-
用文本替换音频可将 token 数减少约 10 倍。对十分钟对话而言,这会让处理的总 token 数——进而输入 token 成本——减少约 100 倍。(因为对话历史每一轮都会复利式增长。) ↩
-
发音、语调、节奏、重音、韵律、情绪效价。 ↩
-
首个音频字节时间。 ↩
-
Azure AI Speech、Amazon Polly 和 Google Cloud Text-to-Speech。 ↩
-
……这也可以推广到软件中的所有事情,也许还包括生活中的大多数事情。 ↩
-
注意 Firefox 的回声消除并不是很好。我们建议语音 AI 开发者以 Chrome 和 Safari 作为主要平台构建,只在时间允许时把 Firefox 作为次要平台测试。 ↩
-
我们最近帮人调试 React Native 应用的音频问题。根因是他们没有意识到自己需要实现回声消除,因为他们没有使用语音 AI 或 WebRTC SDK。 ↩
-
一些高质量音频用例: ↩
-
(或用于保存到文件中。) ↩
-
如果你长期在互联网上构建东西,这有点令人震惊。HTTP 一直是基于 TCP 的协议! ↩
-
古老网络工程师智慧——编者注。 ↩
-
抖动是数据包穿越路由所需时间的可变性。 ↩
-
P95 是某个指标的第 95 百分位测量值。P50 是中位测量值(第 50 百分位)。粗略地说,我们把 P50 看作平均情况,而 P95 捕捉“典型最坏情况”连接的粗略感觉。 ↩
-
尤其是在音频通话中,因为没有视觉线索帮助我们。 ↩
-
Pipecat 的标准 pipeline 配置结合 VAD 和转录事件,试图同时避免误中断和漏掉话语。 ↩
-
标准上下文结构是 OpenAI 发展出的 user / assistant 消息列表格式。 ↩
-
给自己的提醒:让 Claude 想一个好的 Hamlet 笑话——编者注。 ↩
-
如果你对这类话题感兴趣,请考虑加入 Pipecat Discord 并参与那里的讨论。 ↩
-
不过请不要放 Jeopardy 主题曲。 ↩
-
如果你使用 AI 框架,框架很可能会帮你隐藏这种复杂性。 ↩
-
这里把函数调用理解为一个宽泛类别——形式意义上的函数,而非日常口语意义。你可以从查找表返回一个值。你可以运行 SQL 查询。 ↩
-
你可以通过从视频中提取单帧,并把这些帧作为图像嵌入上下文,来用 GPT-4o 和 Claude 处理视频。这种方法有限制,但对某些“视频”用例效果很好。 ↩
-
两个流行的新编程编辑器,具有深度 AI 集成和工具。 ↩
-
见 swyx 在 OpenAI Dev Day 2024 Singapore 的演讲 "Engineering AI Agents"。 ↩
-
Hello, Gemini! ↩
-
即使 OpenAI 和 Google 的 beta speech-to-speech API,也使用专用 VAD 和降噪模型来实现轮次检测。 ↩
-
SOTA —— state of the art —— 是一个广泛使用的 AI 工程术语,大致表示“来自领先 AI 实验室的最新大模型”。 ↩
-
Wharton 教授 Ethan Mollick 提出了“jagged frontier”一词,用来描述 SOTA 模型能力复杂的边界区域——有时惊人地好,有时令人沮丧地差。 ↩
-
如果你有兴趣深入研究提示与微调,请参阅两篇经典论文:Language Models Are Few-shot Learners 和 A Comprehensive Survey of Few-shot Learning。 ↩
-
遵循经典工程建议:先让它工作,再让它快,再让它便宜。在流程的“让它快”阶段中间之前,不要考虑从提示工程转向微调。(如果真的需要的话。) ↩
-
推理模型示例包括 DeepSeek R1、Gemini Flash 2.0 Thinking 和 OpenAI o3-mini。 ↩
-
我们是程序员,当然我们会……——编者注。 ↩
-
通常,你会调用一次 LLM 推理来执行上下文摘要。:-) ↩
-
用户请求是否被满足、智能体是否打断用户、智能体是否跑题等。 ↩
-
当然,前提是假设 AI 智能体表现良好。而对于今天广泛的客户支持用例来说,确实如此。 ↩
-
实际转接操作可能是对你的电话平台的 API 调用,也可能是 SIP REFER 动作。 ↩
-
嗯。这听起来像如今生成式 AI 的其他每个领域。 ↩
-
如果你在本地运行大模型,关于冷启动的建议远超本指南范围。如果你还不是 GPU 和容器优化专家,可能应该找专家,而不是自己爬这条学习曲线(至少在你达到足够大规模、能够摊销开发所需工具成本之前)。 ↩
-
确保你的容器运行时在空闲 CPU 上启动新的智能体进程。这并不总是 k8s 默认行为。 ↩
-
GitHub 用户名,github.com/pipecat-ai/pipecat/graphs/contributors ↩