![]()
简介
Elasticsearch是基于Apace Lunence构建的开源,分布式,具有高可用性和高拓展性的全文检索引擎。Elasticsearch具有开箱即用的特性,提供RESTful接口,是面向文档的数据库,文档存储格式为JSON,可以水平扩展至数以百计的服务器存储来实现处理PB级别的数据。
Elasticsearch可以快速存储,搜索,分析海量,索引数据速度达到毫秒级(近实时Near Real Time)。Github的代码搜索就是使用Elasticsearch来实现的。Elasticsearch使用场景有:
- 网站全文检索,高亮搜索,搜索建议
- 电商网站商品搜索,分面搜索(分面是指事物的多维度属性)
- 基于用户行为的推荐系统
- 支持到PB级别日志数据分析
基本概念
| 术语 | 说明 |
|---|---|
| Node(节点) | 节点是一个Elasticsearch实例。生产环境一般一台机器只运行一个Ealsticsearch |
| Cluster(集群) | 由一个或多个节点组织在一起,共同工作,共同分享整个数据,具有负载均衡和故障转移功能的结构。集群中每个节点可以承担不同的角色 |
| Index(索引) | 是具有相似特征的文档集合,相当于关系型数据库的DB |
| Type(类型) | 7.0之前一个索引中可以定义一种或多种类型,相当于关系型数据库的Table。7.0开始只能创建一个索引只能创建一个Type(_doc) |
| Document(文档) | 文档是存储和检索的基本单元,相当于关系型数据库的Row,文档序列化为JSON格式存储 |
| Field(字段) | 文档里面的最小单位,是JSON对象的字段,相当于关系数据库的Column |
| Shards(分片) | 索引分成若干份,每一份相当于shard,Shard体现了物理空间的概念 |
| Replicas(副本) | 索引的拷贝。用于负载均衡和保证数据读取的吞吐量和高可用 |
| Mapping(映射) | 每个索引都有自己的Mapping定义,用于定义包含的文档的字段字段名和字段类型,类似关系型数据字段类型 |
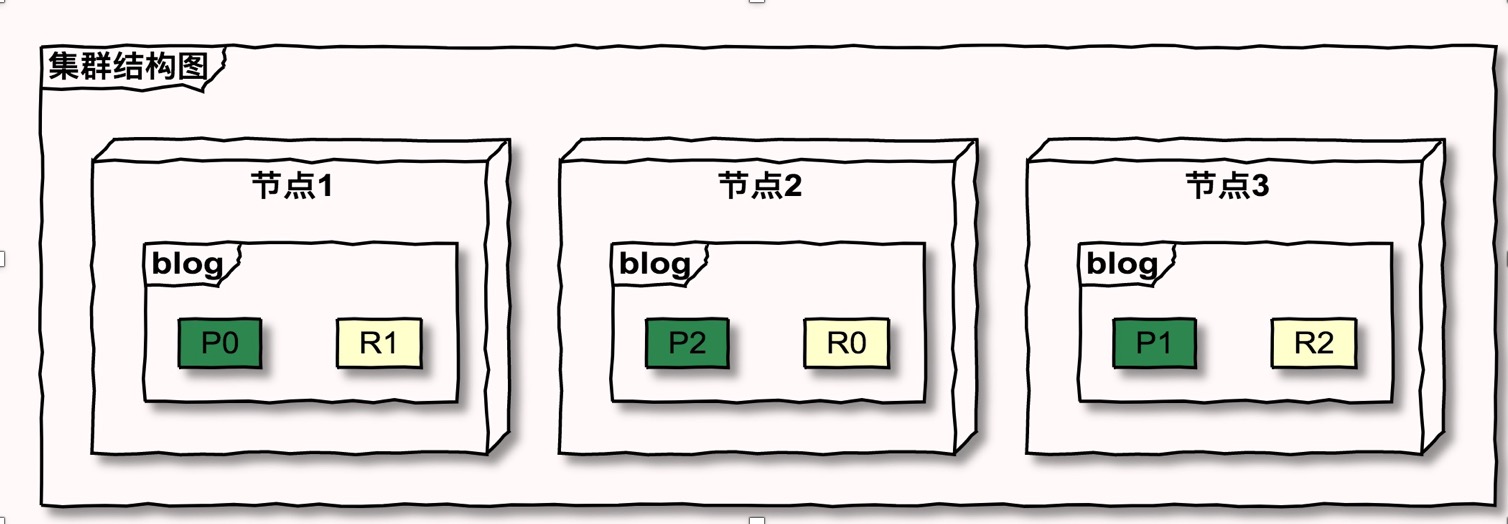
节点
一个节点就是一个Elasticsearch的实例,每个节点需要显示指定节点名称,可以通过配置文件配置,或者启动时候-E node.name=node1指定
节点类型
每个节点在集群承担承担不同的角色,也可以称为节点类型。
候选主节点(Master-eligible nodes)和主节点(Master Node)
- 每个节点启动之后,默认就是一个Master eligible节点,Master-eligible节点可以参加选主流程,成为Master节点
- 当第一个节点启动时候,它会将自己选举成为Master节点
- 在每个节点上都保存了集群的状态信息,但只有Master节点才能修改集群的状态信息。集群状态(Cluster State)中必要信息包含
- 所有节点的信息
- 所有的索引,以及其Mapping与Setting信息
- 分片的路由信息
数据节点(Data Node)和协调节点(Coordinating Node)和Ingest节点
- Data Node
- 用于保存数据的节点。负责保存分片的数据,在数据拓展上起到至关重要的作用
- Coorination Node
- 负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到Cooridinating Node的职责,这就意味着如果一个node,将node.master,node.data,node.ingest全部设置为false,那么它就是一个纯粹的coordinating Node node,仅仅用于接收客户端的请求,同时进行请求的转发和合并
- Ingest节点
- 可以运行pipeline脚本,用来对document写入索引文件之前进行预处理的
在生产环境部署上可以部署dedicate的 Ingest Node 和 Coordinate node,在前端的Load Balance前面增加转发规则把读分发到coording node,写分发到 ingest node。 如果集群负载不高,可以配置一些节点同时具备coording和ingest的能力。然后将读写全部路由到这些节点。不仅配置简单,还节约硬件成本
其他类型节点
-
冷热节点(Hot & Warm Node)
- 不同硬件配置的Data Node,用来实现Hot & Warm架构,降低集群部署的成本。通过设置节点属性来实现
-
机器学习节点(Machine Learning Node)
- 负责跑机器学习的Job,用来异常检测
节点类型配置:
- 开发环境一个节点可以承担多种角色
- 生产环境中,应该设置单一的角色的节点,即dedicated node
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| 候选主节点 | node.master | true |
| 数据节点 | node.data | true |
| ingest节点 | node.ingest | true |
| 协调节点 | 无 | 每个节点默认都是协调节点 |
| 机器学习节点 | node.ml | true |
查看节点信息
我们可以通过以下API查看节点信息
1 | GET /_cat/nodes?v |
返回信息如下:
1 | ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name |
返回信息说明:
-
node.role值mdi是master,data,ingest首字母缩写,说明172.31.0.2节点承担着master,data,ingest角色。
-
master值是*(星号),说明该节点被选主成主节点
-
name值是zy1AwuM,说明节点名称是zy1AwuM
查看节点属性
通过下面的API,我们可以查看节点属性信息
1 | GET /_cat/nodeattrs?v |
文档(Document)
- Elasticsearch是面向文档的Nosql,文档是可以搜索的数据的最小单位
- 文档以序列化的Json格式存储,Json对象有字段组成,每个字段都有对应的字段类型。字段类型可以由Elasticsearch自动推断,或者手动指定(通过为索引创建Mapping)
- 每个文档都有一个唯一ID。该ID可以由Elasticsearch自动生成,或者自己指定
索引(Index)
索引是是具有相似特征的文档集合,相当于关系型数据库的DB。每个索引都用自己的Mapping,用于定义索引包含的文档的Json对象的字段名称和类型。
索引可以分成若干份,可以存储在不同节点上。每一份索引相当于一个Shard。shard规则可以简单认为根据文档ID哈希处理之后,取主分片的模
1 | shard = hash(document_id) % number_of_primary_shards |
索引的主分片数是用过Settings来设置,它与Mapping(映射)区别是:
- Mapping定义文档字段的类型
- Setting定义主分片数,副本数
我们可以通过一下命令查看索引Index信息:
1 | GET _cat/indices |
类型(Type)
7.0 开始一个索引只能创建一个Type, 即_doc,在此之前一个索引可以设置多个Type
主分片和副本分片(Primary Shard & Replica Shard)
主分片
主分片用以解决数据水平拓展的问题。通过主分片,可以将数据分布到集群内的所有节点上。
- 一个分片是一个运行的Luncene的实例
- 主分片数在索引创建是指定,后续不允许修改,除非Reindex
副本
副本用以解决数据高可用的问题。副本是主分片的拷贝。当副本没有可用节点分配时候,集群状态是Yellow。
- 副本分片数,可以动态调整
- 增加副本数,在一定程度上提高读取的吞吐,提高服务的可用性
对于生成环境中分片的设定,需要提前做好容量规划,分片设置过程容易出现的问题:
- 分片数设置过小
- 后续无法通过增加节点实现水平拓展
- 单个分片的数量过大,导致查询以及数据重新分配耗时过长
- 分片数设置过大
- 分片过大导致over-sharding问题
- 单个节点上过大的分片,会导致资源浪费,也会影响性能
- 影响搜索结果的相关性打分,影响统计结果的准确性。7.0开始默认主分片设置成1
数据类型
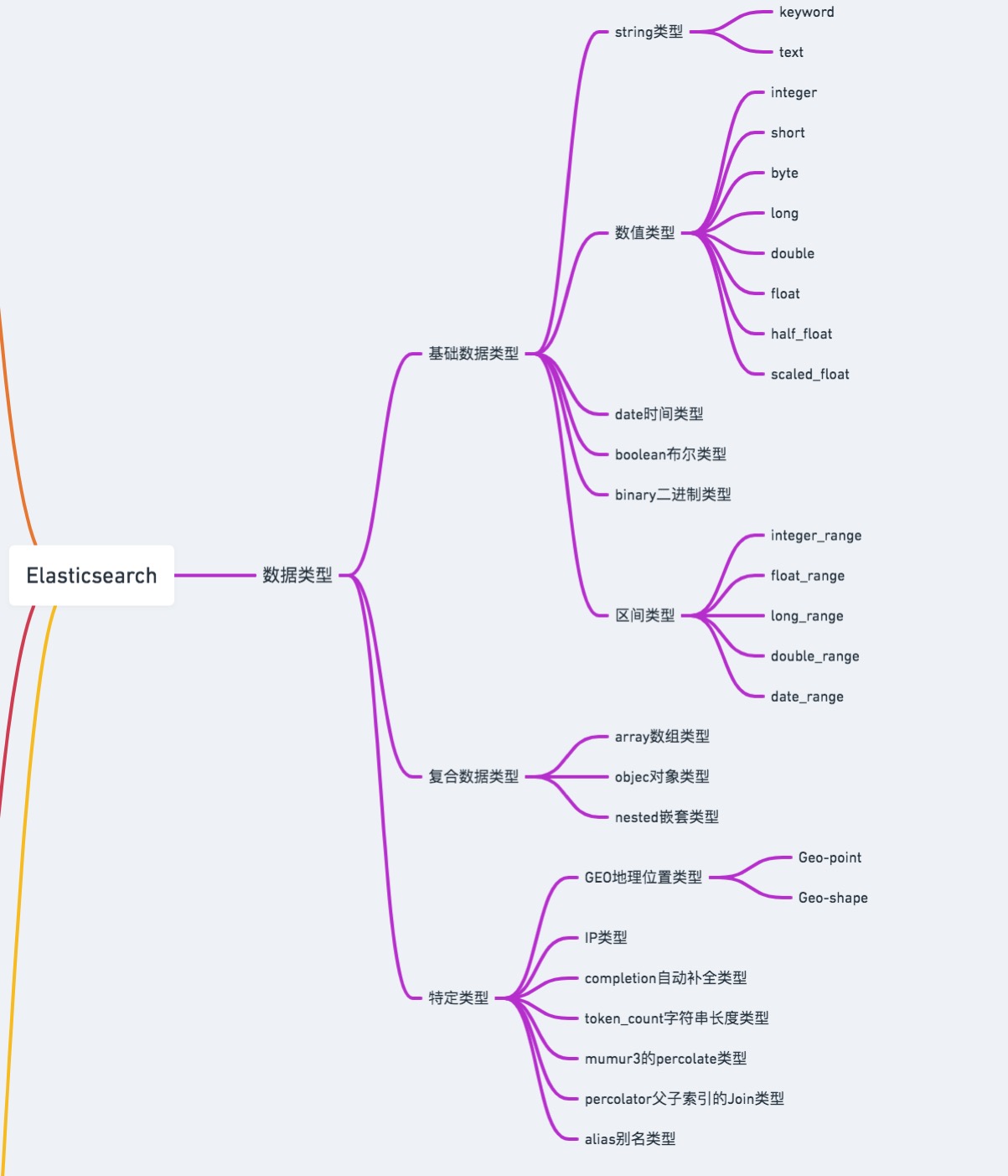
Elasticsearch中支持的数据类型非常丰富:
String类型
- text:会被分词处理,用于全文检索,很少用于聚合处理(需要设置fielddata属性),不能用于排序
- keyword:不可分词,用于精确搜索,过滤、排序、聚合等操作
Number类型
数字类型有如下分类:
| 类型 | 说明 |
|---|---|
| byte | 有符号的8位整数, 范围: [-128 ~ 127] |
| short | 有符号的16位整数, 范围: [-32768 ~ 32767] |
| integer | 有符号的32位整数, 范围: [−231 ~ 231-1] |
| long | 有符号的64位整数, 范围: [−263 ~ 263-1] |
| float | 32位单精度浮点数 |
| double | 64位双精度浮点数 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数, 比如price字段只需精确到分, 57.34缩放因子为100, 存储结果为5734 |
应当尽可能选择范围小的数据类型, 字段的长度越短, 索引和搜索的效率越高;优先考虑使用带缩放因子的浮点类型
Date类型
Date类型在Elasticsearch中以数值形式(long类型)存储。文档在索引Date类型数据时候,会根据format选项来指定日期格式,Elasticsearch默认解析ISO 8601格式字符串。format选项有:
-
格式化的日期字符串
比如yyyy-MM-dd格式的,2020-01-01,还有ISO8601格式的2020-01-01T05:04:03Z
-
毫秒数
比如1584930153000
-
秒数
比如1584930153
-
多种格式混合
多个格式使用双竖线||分隔,每个格式都会被依次尝试, 直到找到匹配的,比如
yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis
Boolean类型
- 真值,表示真值的有true,“true”, “on”, “yes”, “1”
- 假值,表示假值的有false, “false”, “off”, “no”, “0”, “”, 0.0, 0
文档的CRUD操作
不同于关系型数据库的写时模式(schema on write),Elasticsearch属于读时模式(schema on read)。在写入文档时候不需要明确设置各个字段类型,Elasticsearch会自动出推断字段类型。在真实项目中,我们应该明确通过设置索引的Mapping来指定字段和字段。
文档创建(Create)
1 | POST /game/_doc |
若文档创建成功,Elasticsearch会返回元数据和一个 201 Created的 HTTP状态码:
1 | { |
以下划线(_)开头的字段属于Elasticsearch元信息(meta data).
-
_index
索引名称,相当于mysql里面的数据库名称
-
_type
索引类型,相当于mysql里面的表名
-
_id
文档唯一ID。_index,_type,_id唯一标识了系统里面的一个文档。在未定文档ID时候,Elasticsearch会自动生成文档ID。自动生成的 ID 是基于 Base64编码、URL-safe、且长度为20个字符的 GUID 字符串。 这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一ID ,且互相之间的冲突概率几乎为零。
-
_version
版本号,Elasticsearch使用版本号来进行并发控制
-
result
操作结果,创建成功时created
手动指定文档ID:
1 | PUT /game/_doc/2?op_type=create |
或者
1 | PUT /game/_doc/2/_create |
若文档已存在,Elasticsearch将会返回409 Conflict状态码,以及如下的错误信息:
1 | { |
索引文档(Index)
此时Index为动词,是将文档写入到elasticsearch里面。在文档不存在的情况下,与指定文档ID创建文档操作本质一样。在文档以存在情况下,会更新文档信息(在内部,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。 ,但它并不会立即消失。当继续索引更多的数据,Elasticsearch会在后台清理这些已删除文档, 此操作也叫Index操作),此时_version会加一,result是updated
1 | POST /game/_doc/2 |
查看文档(Read)
1 | GET /game/_doc/2 |
文档存在时候响应内容如下:
1 | { |
-
found
值为true(找到指定文档), false(未找到指定文档)
-
_source
source字段返回文档所有内容
若文档不存在,Elasticsearch会返回404 Not Found状态码, found值为false
文档更新(Update)
1 | POST /game/_doc/2/_update |
更改name字段值,新增一个views字段,此时候文档版本号_version会更新。
若要更新全部文档则需要使用文档索引操作
删除文档(Delete)
1 | DELETE /game/_doc/2 |
若文档不存在,Elasticsearch会返回404 Not Found状态码, result是not_found:
1 | { |
即使文档不存在, _version 值仍然会增加。这是 Elasticsearch内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
批量操作(Batch)
批量取文档-mget
文档在同一个索引内,可以把多个文档ID放入ids数组中批量查询
1 | GET /game/_doc/_mget |
文档在多个索引中:
1 | GET /_mget |
Bulk操作
通过Bulk API,我们可以一次性进行多种类型操作:
- Index
- Create
- Update
- Delte
Bulk API 支持对不同的索引操作,单条操作成功或失败,不影响其他操作结果。返回结果包括了每一条操作的结果
Bulk API请求体格式如下:
1 | { action: { metadata }}\n |
action/metadata指定对哪个索引,哪个文档进行何种类型操作,操作类型只能是上面四种:
1 | POST /_bulk |
索引或者类型都一样的时候,我们可以在URL指定索引和类型,那么请求体中就不需要在指定索引和类型。若请求体中指定了,则会覆盖掉URL中的索引和类型
1 | POST /website/_bulk |