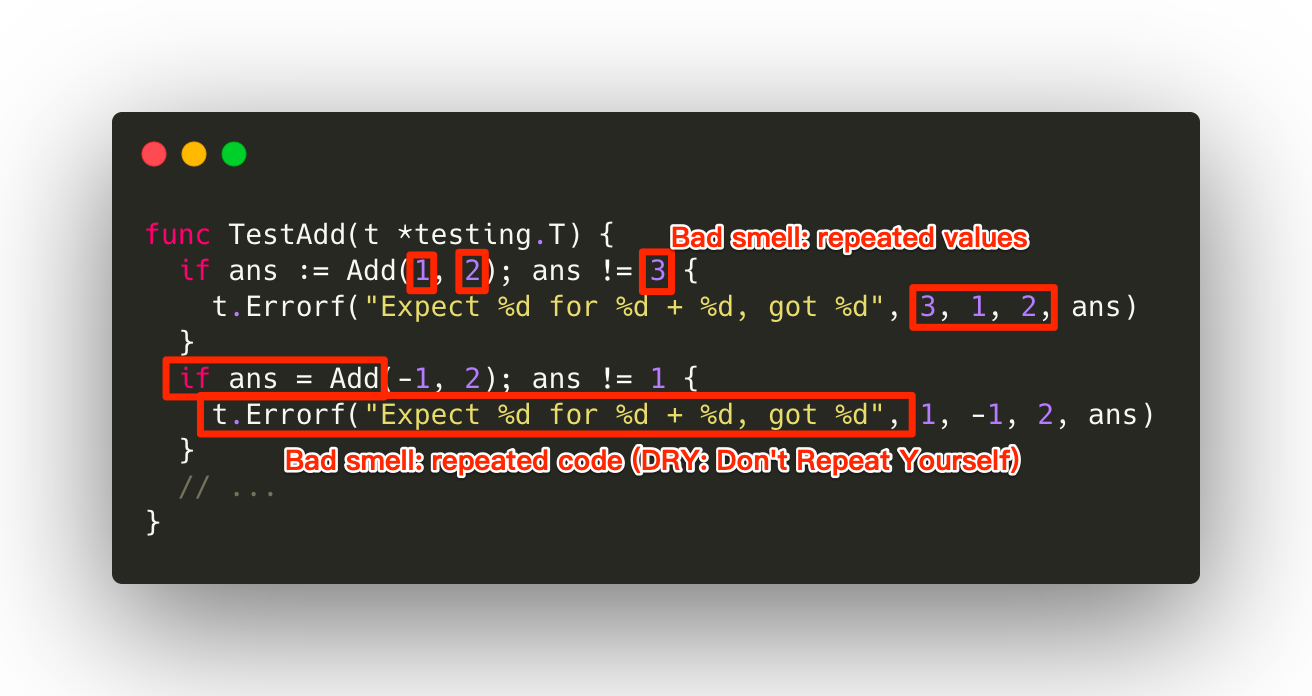
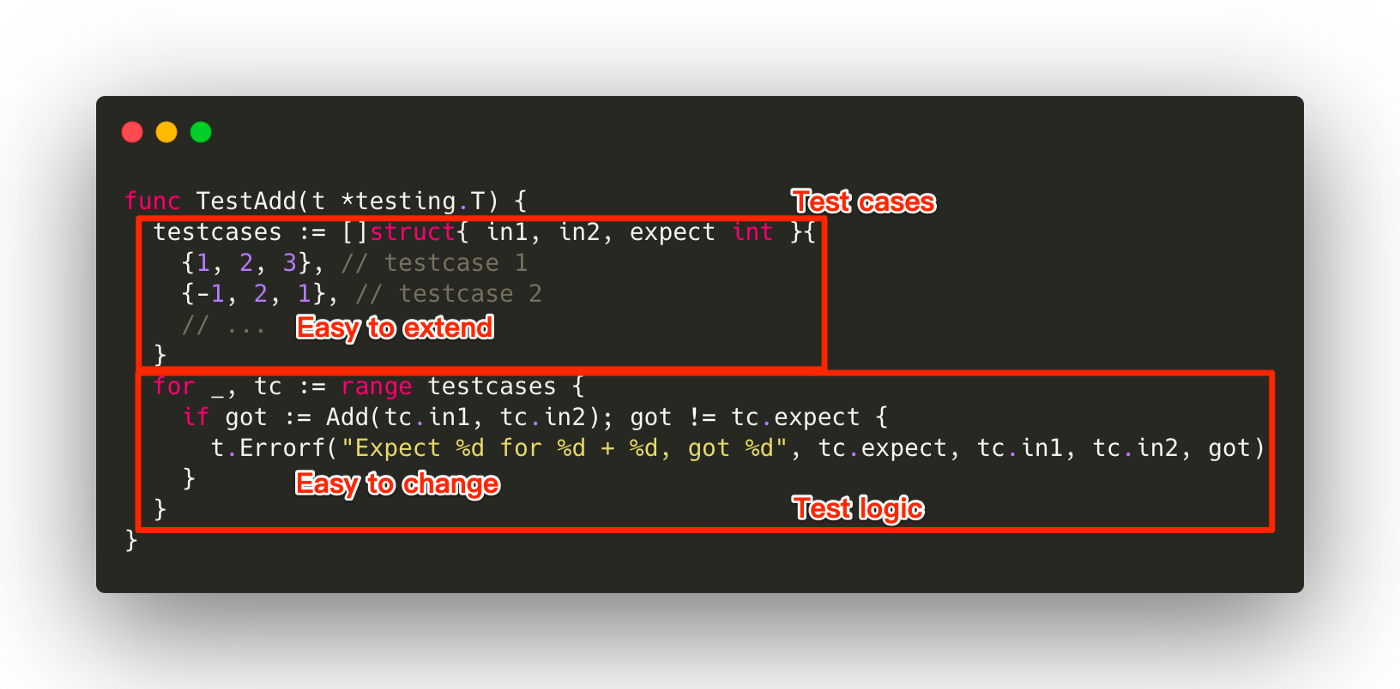
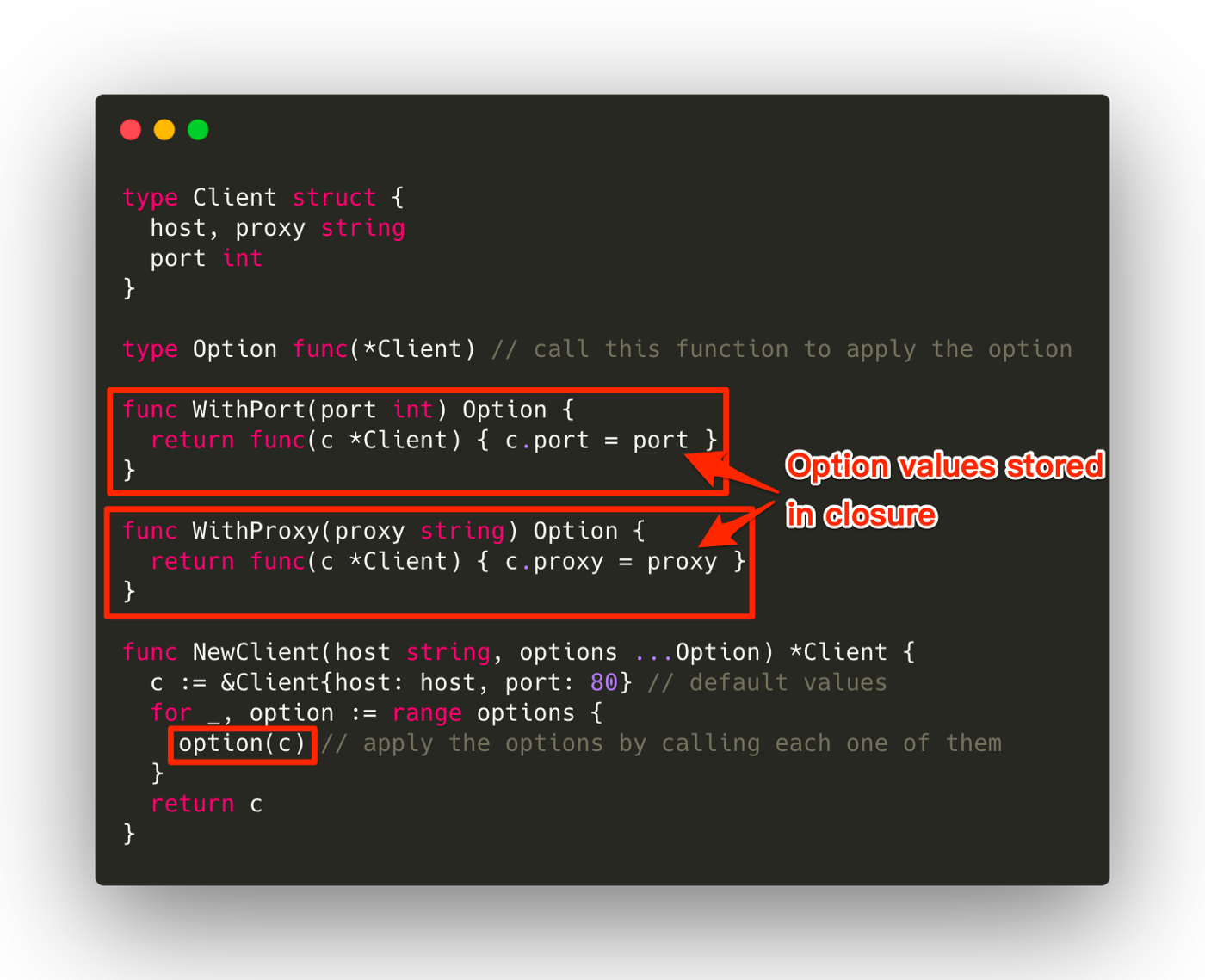
let s1 = String::from("hello"); // Create complex data type which involves the use of the heap let s2 = s1; // This "moves" the data from s1 to s2 (s2 owns the data), s1 is no longer valid
println!("{}", s1); // The compiler will throw an error here, s1 is no longer valid!
// We can't do much with a disabled GPIO pin, let's convert it // into an input pin let input_pin = pin.into_enabled_input_pin();
// We can now read the state of the pin let pin_state = input_pin.is_set();
input_pin.set(); // We can't set an input, this produces a compile time error!
// We've changed our minds, we now want it to be an output! This // is easy to do, again it "consumes" the input_pin object let output_pin = input_pin.into_enabled_output_pin();
fnmain() { let arr: [i8; 3] = [1, 2, 3]; // Rust will throw a compiler error on the next line, since it can work out a compile time that this // index is out of bounds let _ = arr[3]; }
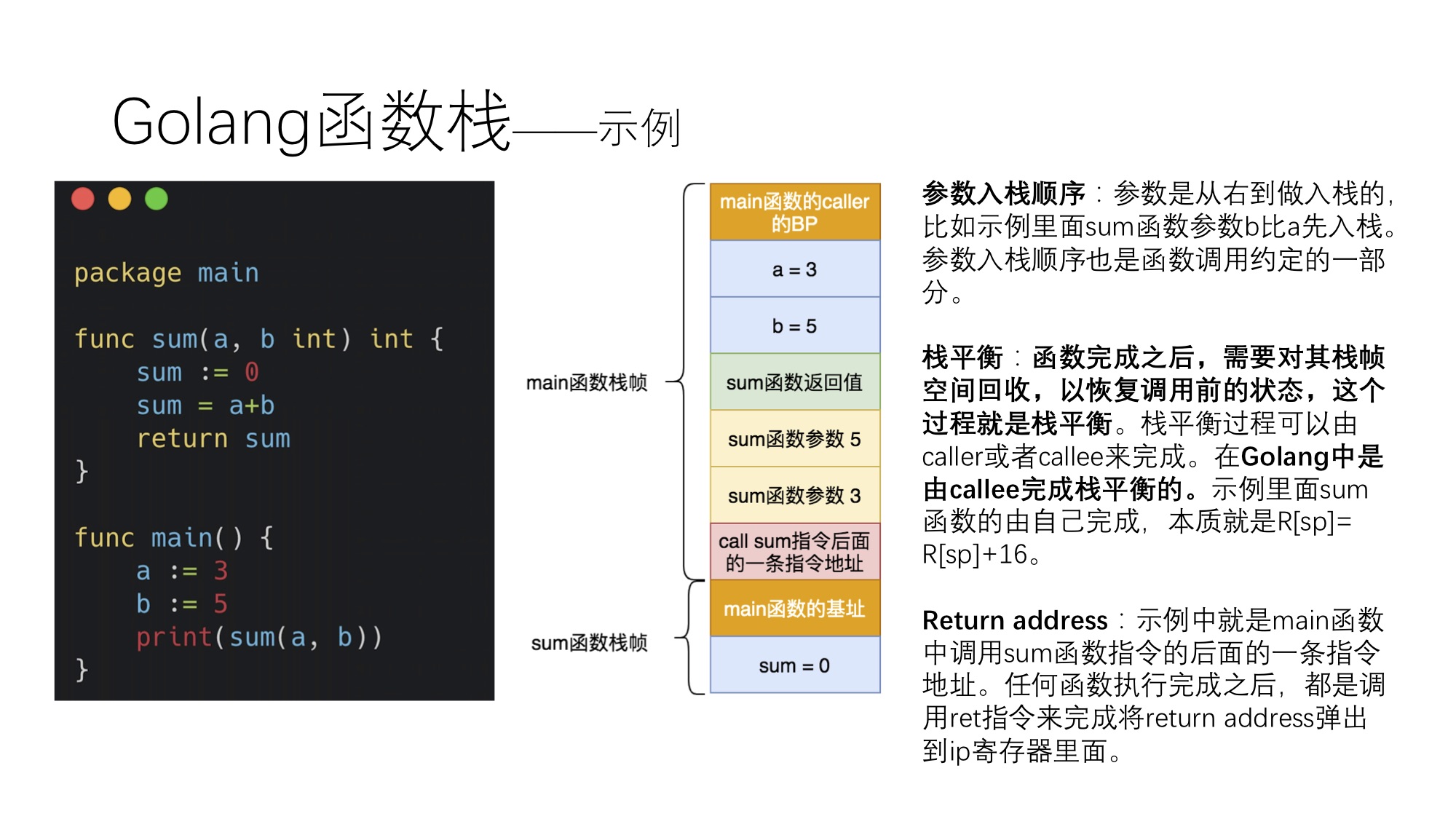
在 Rust 中,你还可以使用临界区来防止中断中的数据竞争。nb 库采用了一种有趣的方法来解决决定 API 调用是否应该阻塞(或如何阻塞!)的问题。它允许编写 API 的人编写核心功能,然后让调用者决定阻塞行为。 API 返回 nb::Result<T, Error> 类型,其中 T 是函数的标准返回类型。如果调用者确实想要阻塞等待函数完成,他们可以将调用包装在块中 block!。nb 库有一定的潜力与 HAL 外设一起使用,例如 UART的 read/write() 函数(通常会阻塞,直到发送/接收数据)。
错误处理
在大多数语言中,有两种常见的错误处理方式。
返回错误代码
抛出异常
在嵌入式固件中,有时由于执行时间不可预测(尽管与普遍认识相反,异常实际上可以改进非异常情况下的运行时性能)或增加了每个开发者都必须注意的复杂性,需要禁止使用异常。返回错误代码是许多嵌入式项目的标准错误处理方式,但你必须记住检查错误并将它们适当地传播到调用堆栈。Rust 的 Result 类型,它可以极大地改善错误处理体验。
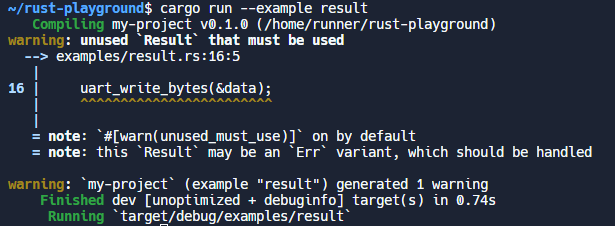
fnuart_write_bytes(bytes: &[u8]) -> Result<usize, &'staticstr> { if bytes.len() > 10 { returnErr("Can only write 10 bytes or less!"); } // Write bytes here // ....
// Writing completed successfully, return number of bytes written Ok(bytes.len()) }
如果我们尝试使用这个函数并且忘记检查返回的结果,Rust 会产生警告,例如如果我们这样写:
1 2
let data = [32, 38, 24, 34]; uart_write_bytes(&data); // Oh oh, we've forgotten to check for an error
Rust 会抛出如下错误:
如何正确处理这个返回的 Result 对象呢?一种方法是调用 unwrap()。如果没有错误,unwrap() 将返回该值;如果有错误,则会出现恐慌。在错误不可恢复的情况下,你可以使用 unwrap(),并且在嵌入式情况下,你可以定义恐慌的作用(将其视为与 C/C++ 断言相同)。
1 2
// Using unwrap() we can unpack the returned `Result` type, we either get the number of bytes if write was successful or panic if `Err` was returned let num_bytes = uart_write_bytes(&data).unwrap();
还有 Expect() ,它与 .unwrap() 类似,只不过它还允许你提供自定义错误消息:
1
let num_bytes = uart_write_bytes(&data).expect("Writing bytes to UART failed.");
如果错误是可恢复的和/或预期的,则可以在 Result 对象上使用 match 语句来适当地处理错误情况。
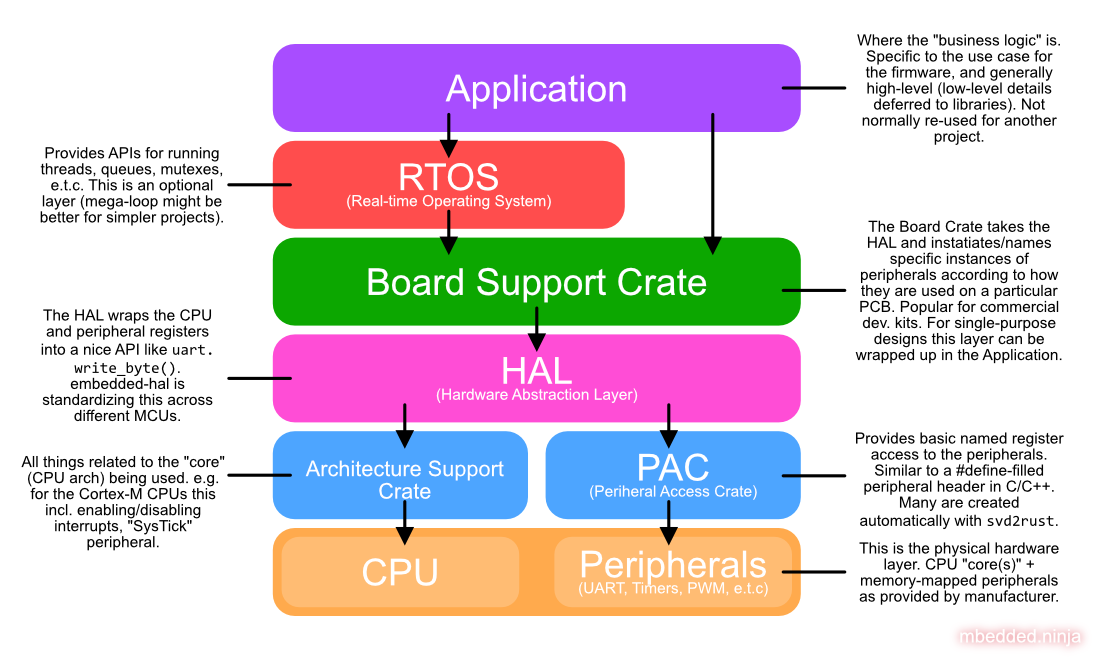
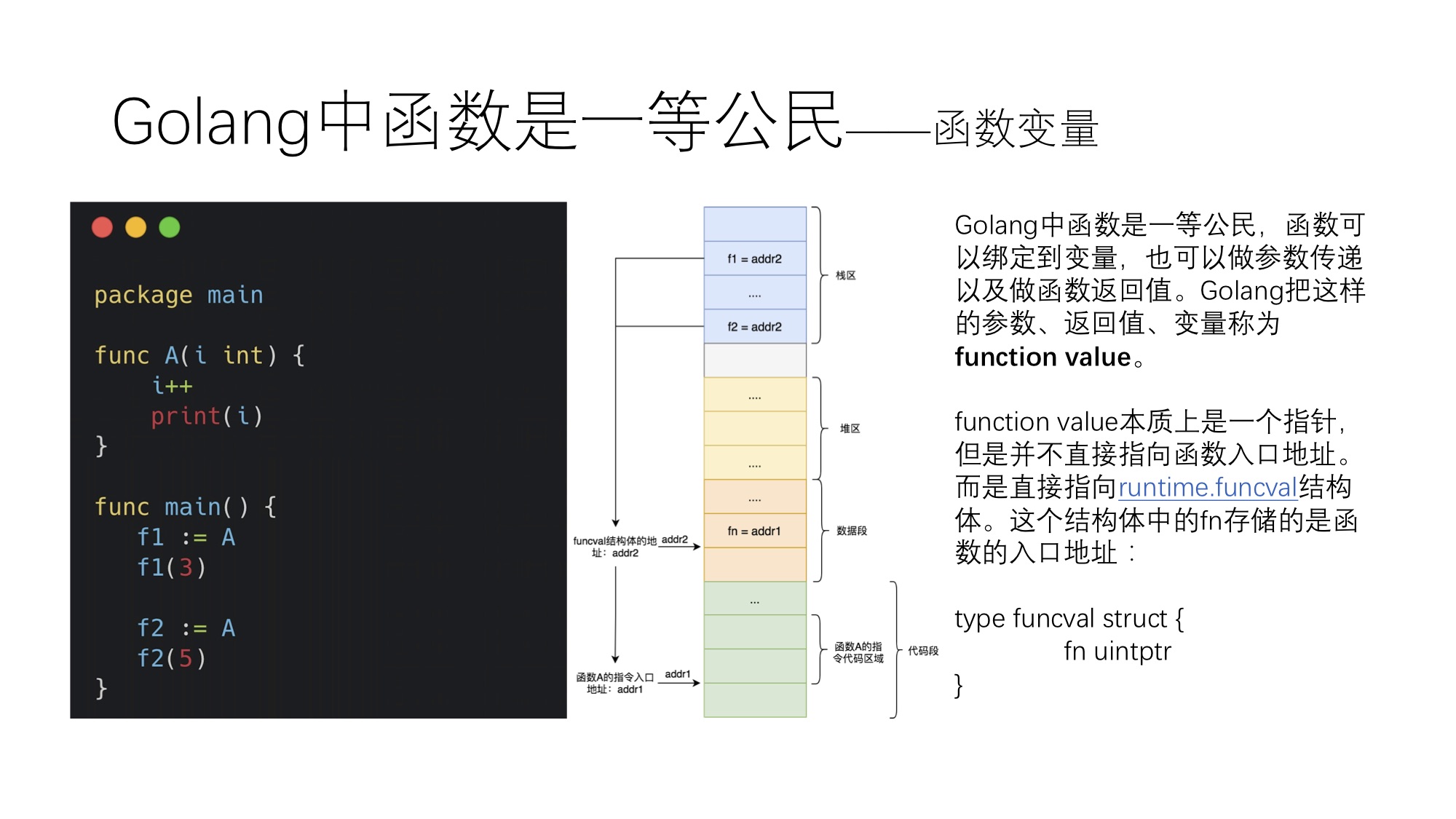
板级支持包(Board Support Crate): 该包是为包含微控制器的特定 PCB 项目而构建的。 板级支持包使用 HAL 并根据 MCU 与物理世界的连接方式创建适当命名的 HAL 对象实例。这是一个可选的额外包,如果你正在设计一个可供许多人用于许多不同目的的板子,那么创建板级支持包这是一个好主意。对于一次性项目,创建板级支持包的额外开销可能不值得,相反,你可以将此代码捆绑在应用程序中。
你可以使用在线编辑器/编译器(例如 Replit)来尝试 Rust。或者,如果你更喜欢在本地运行某些内容,请安装 cargo,然后使用 cargo new hello_world --bin 初始化一个新项目(这将用于在你的计算机上运行,而不是在微控制器上运行)。
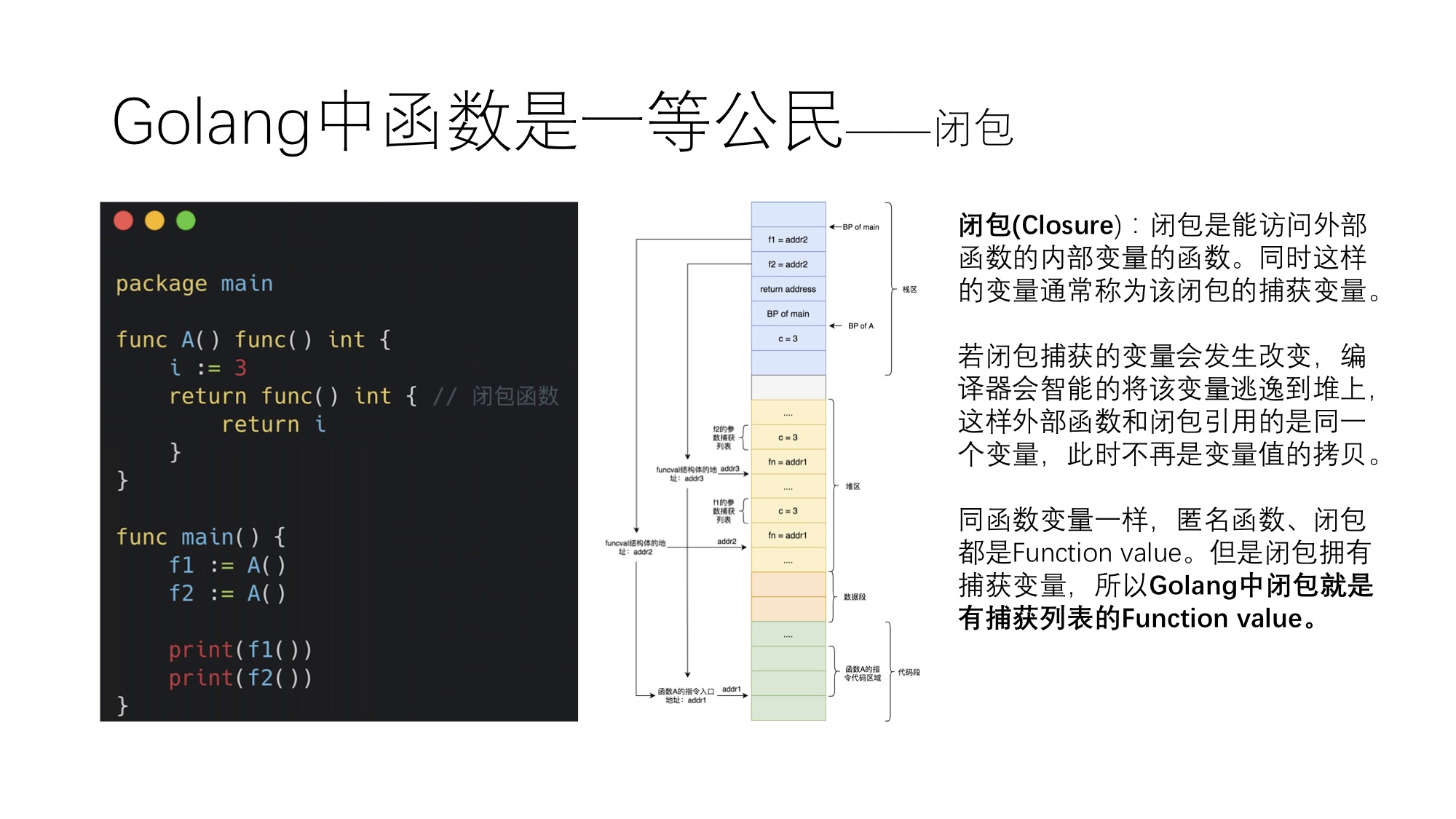
引用
1.Wikipedia (2022, Nov 11). Rust (programming language). Retrieved 2022-11-19, from https://en.wikipedia.org/wiki/Rust_(programming_language) ↩
2.Rust Embedded. Embedded Devices Working Group (repository). GitHub. Retrieved 2022-11-12, from https://github.com/rust-embedded/wg ↩
3.Rust Embedded. The Embedded Rust Book. Retrieved 2022-11-14, from https://docs.rust-embedded.org/book/ ↩
4.vd2rust. Crate svd2rust (documentation). Retrieved 2022-11-14, from https://docs.rs/svd2rust/latest/svd2rust/ ↩
5.Embedded HAL. Module embedded_hal::serial (documentation). Retrieved 2022-12-05, from https://docs.rs/embedded-hal/latest/embedded_hal/serial/ ↩
6.Rust Language Docs. Macro std::line. Retrieved 2022-11-29, from https://doc.rust-lang.org/std/macro.line.html ↩
7.rust-lang. The rustup book: Cross-compilation. Retrieved 2022-11-14, from https://rust-lang.github.io/rustup/cross-compilation.html ↩
8.rust-lang. The rustc book: Platform Support. Retrieved 2022-11-15, from https://doc.rust-lang.org/nightly/rustc/platform-support.html ↩
9.ARM Developer. Processors: Cortex-M3. Retrieved 2022-11-15, from https://developer.arm.com/Processors/Cortex-M3 ↩
10.ARM Developer. Processors: Cortex-M4. Retrieved 2022-11-15, from https://developer.arm.com/Processors/Cortex-M4 ↩
11.Rust Embedded. alloc-cortex-m - A heap allocator for Cortex-M processors (repository). Retrieved 2022-11-30, from https://github.com/rust-embedded/alloc-cortex-m ↩
12.atsamd-rs. atsamd & atsame support for Rust (Git repository). Retrieved 2022-11-21, from https://github.com/atsamd-rs/atsamd ↩
13.nrf-rs. nrf-hal (Git repository). Retrieved 2022-11-14, from https://github.com/nrf-rs/nrf-hal ↩
14.rp-rs GitHub Organization. Rust support for the “Raspberry Silicon” family of microcontrollers. Retrieved 2022-11-28, from https://github.com/rp-rs/rp-hal ↩
15.rust-embedded/book. Discourage use of semihosting and mention viable alternatives #257 (GitHub issue). Retrieved 2022-12-05, from https://github.com/rust-embedded/book/issues/257 ↩
17.rust-gcc. GCC Front-End For Rust - Homepage. Retrieved 2022-12-11, from https://rust-gcc.github.io/. ↩
// The C string is allocated in the C heap using malloc. // It is the caller's responsibility to arrange for it to be // freed, such as by calling C.free (be sure to include stdlib.h) funcC.CString(string) *C.char
// Go []byte slice to C array // The C array is allocated in the C heap using malloc. // It is the caller's responsibility to arrange for it to be // freed, such as by calling C.free (be sure to include stdlib.h) funcC.CBytes([]byte)unsafe.Pointer
C 类型字符串转换成Go 类型:
1 2 3 4 5 6 7 8
// C string to Go string funcC.GoString(*C.char)string
// C data with explicit length to Go string funcC.GoStringN(*C.char, C.int)string
// C data with explicit length (in bytes) to Go []byte funcC.GoBytes(unsafe.Pointer, C.int) []byte
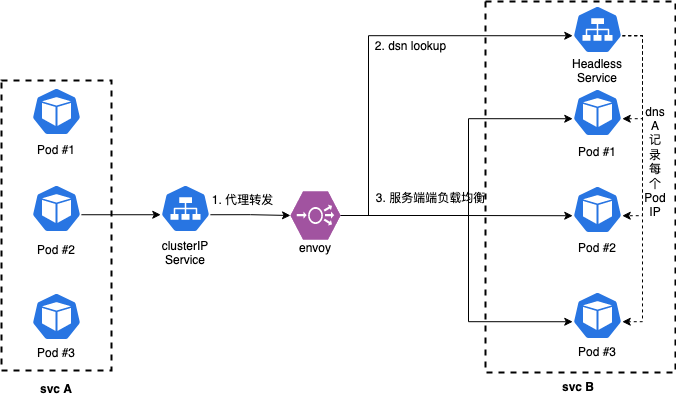
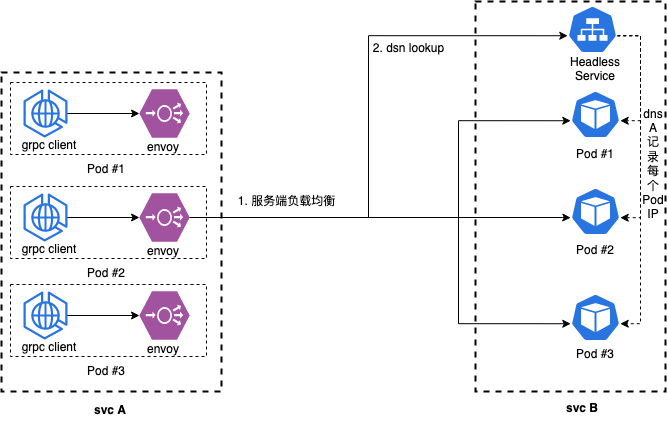
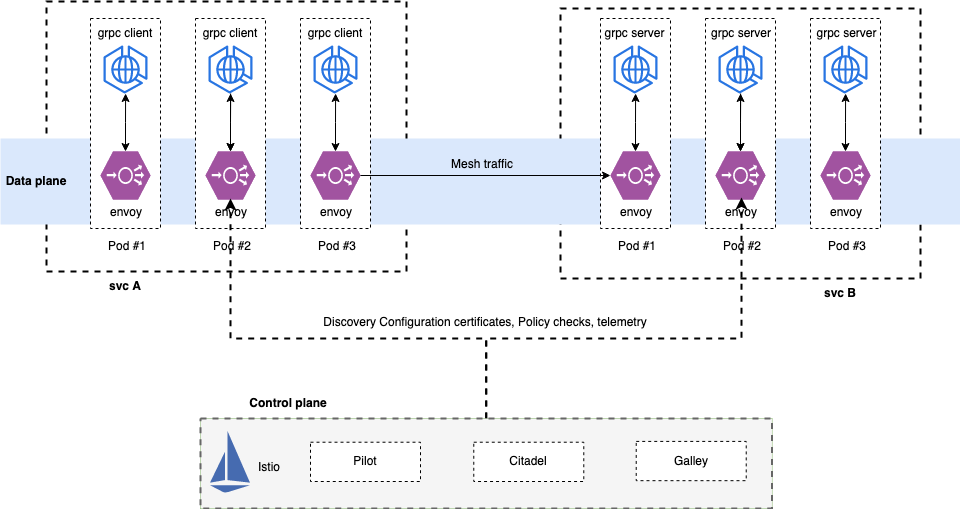
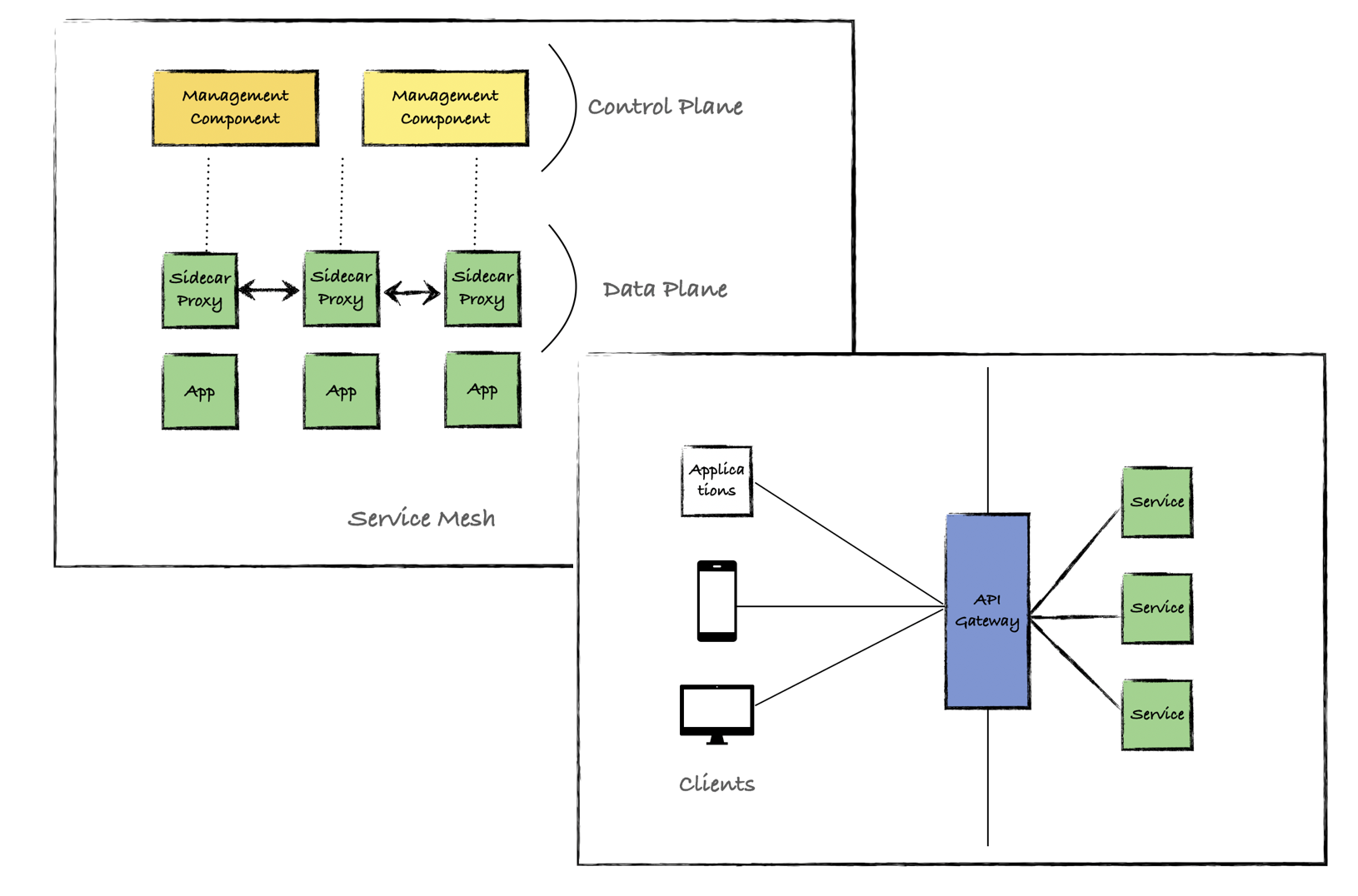
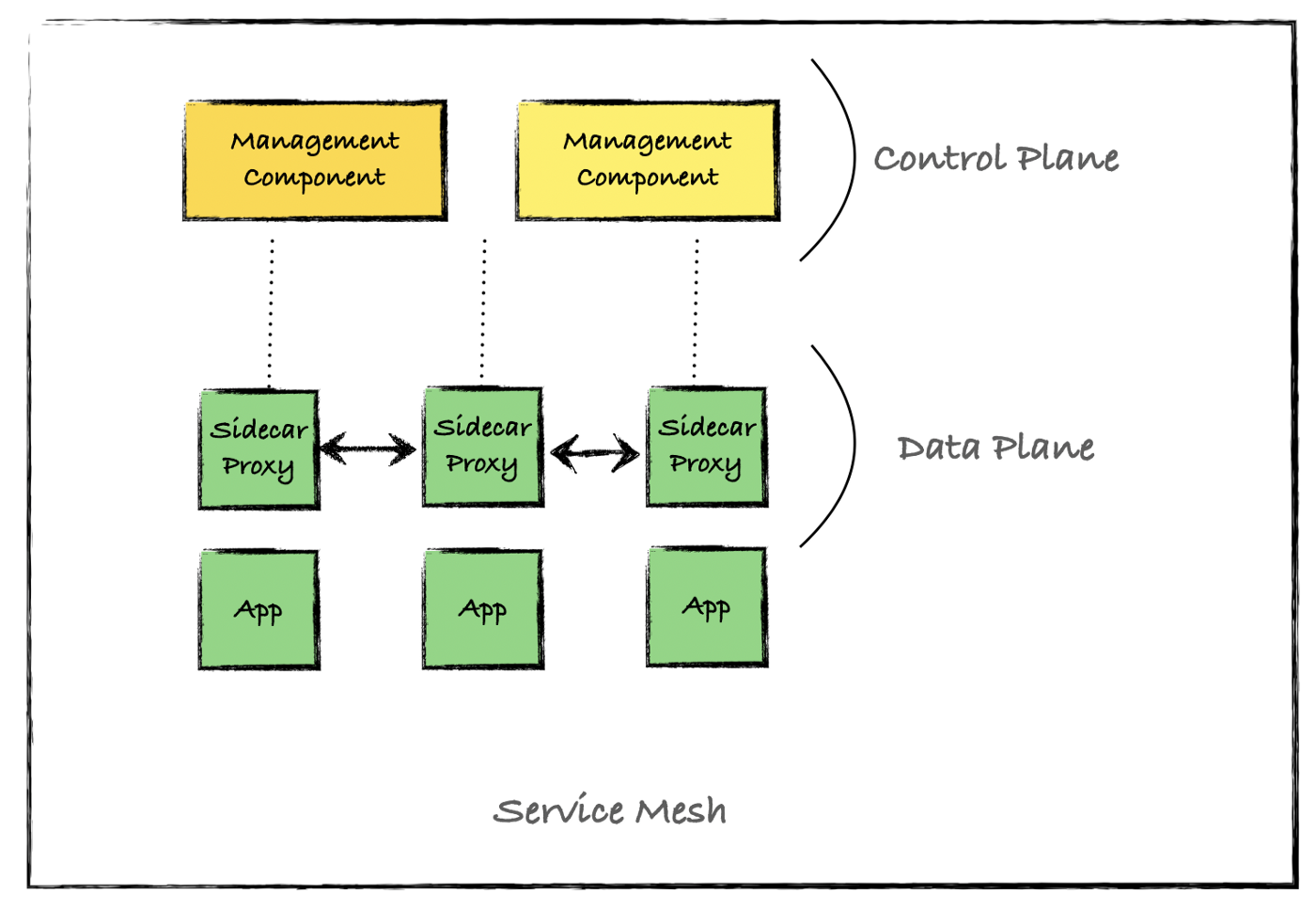
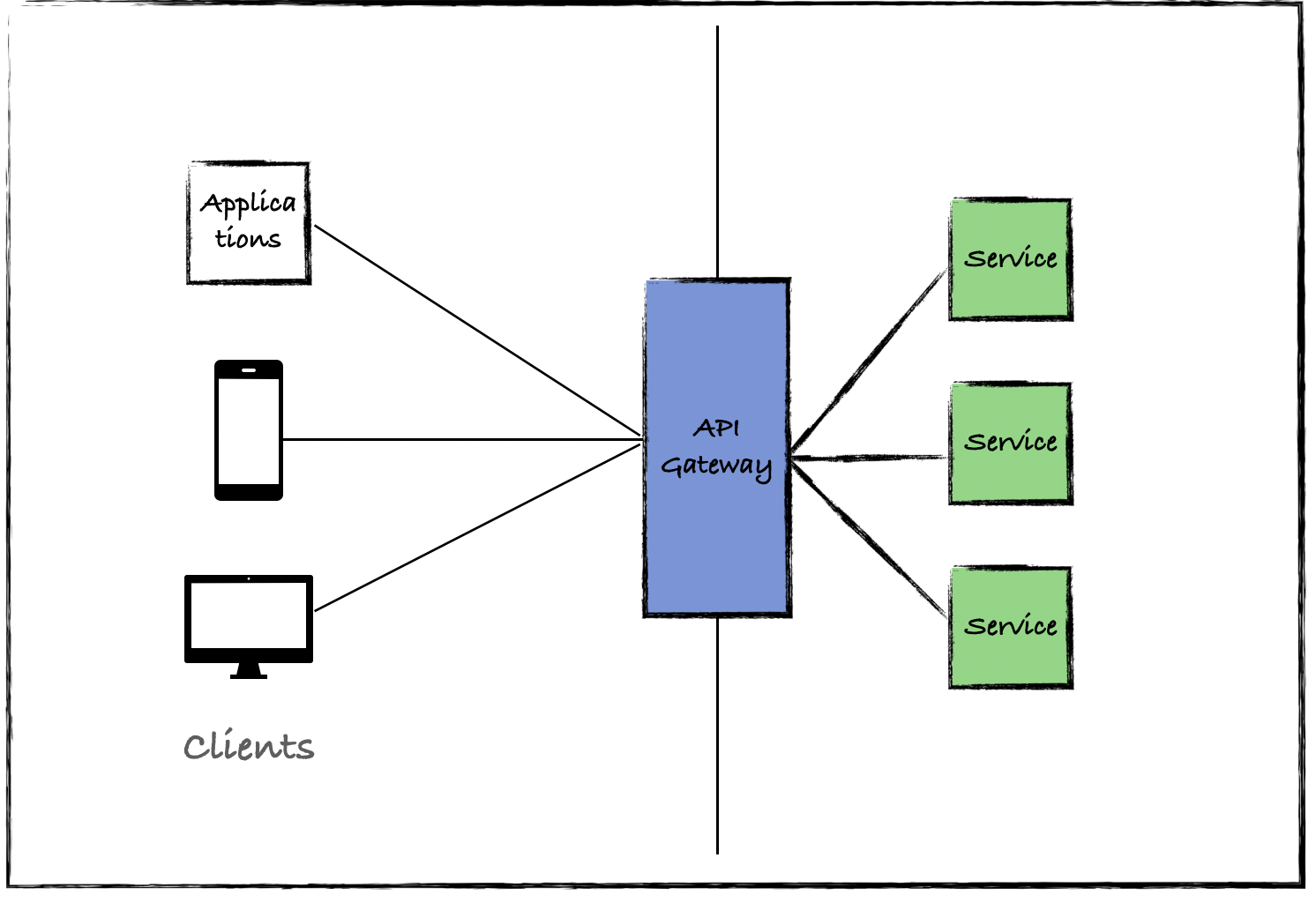
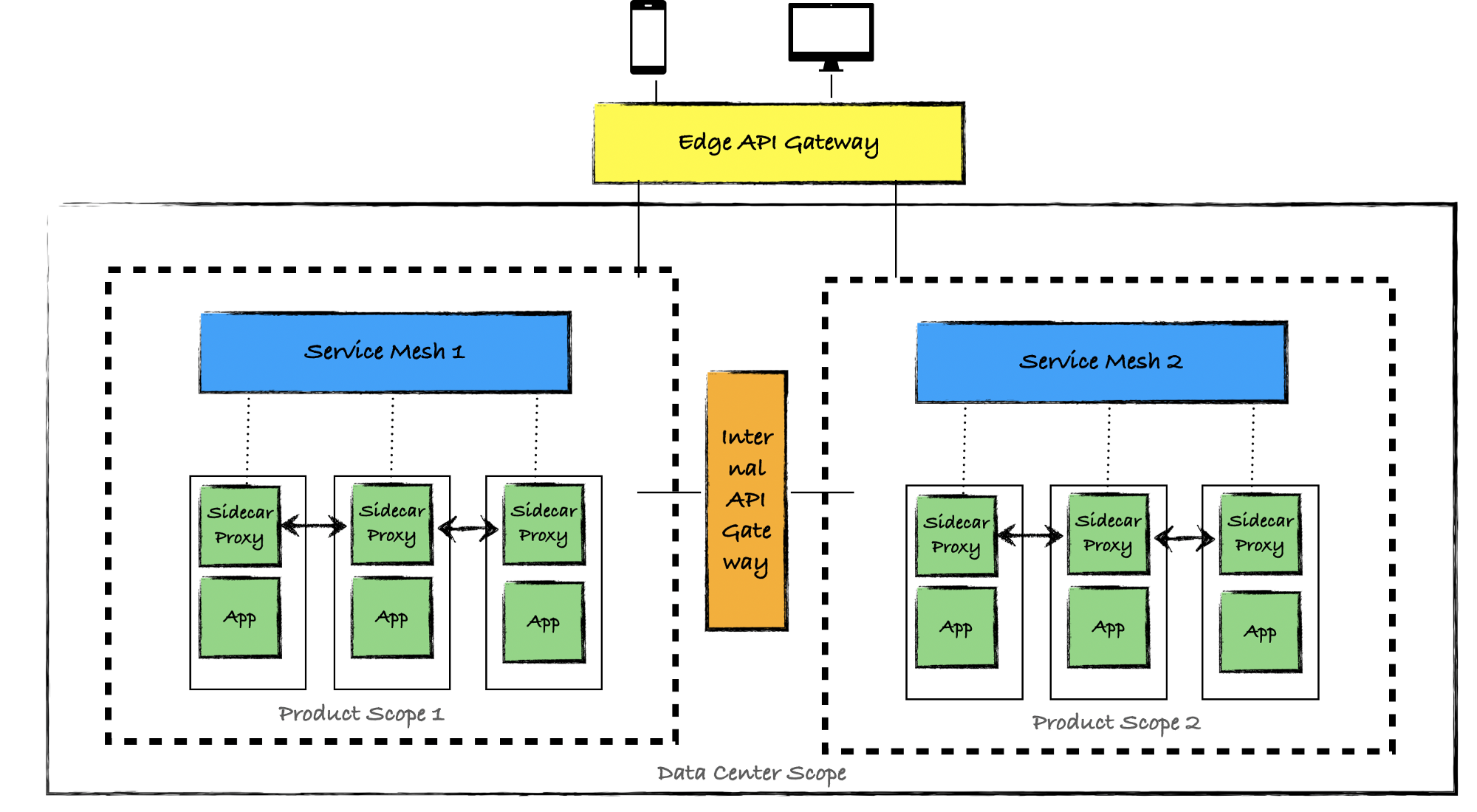
gRPC uses the performance boosted HTTP/2 protocol. One of the many ways HTTP/2 achieves lower latency than its predecessor is by leveraging a single long-lived TCP connection and to multiplex request/responses across it. This causes a problem for layer 4 (L4) load balancers as they operate at too low a level to be able to make routing decisions based on the type of traffic received. As such, an L4 load balancer, attempting to load balance HTTP/2 traffic, will open a single TCP connection and route all successive traffic to that same long-lived connection, in effect cancelling out the load balancing.
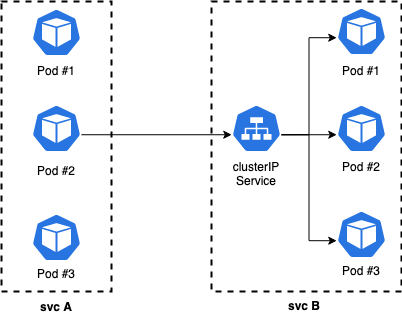
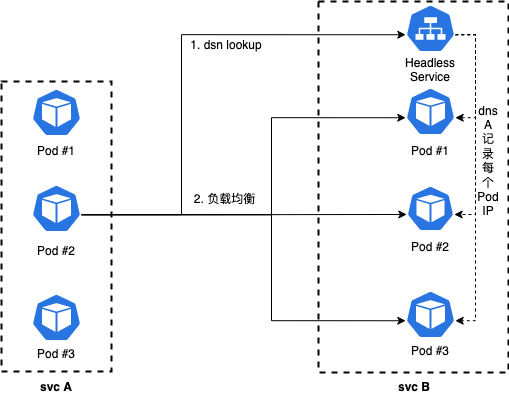
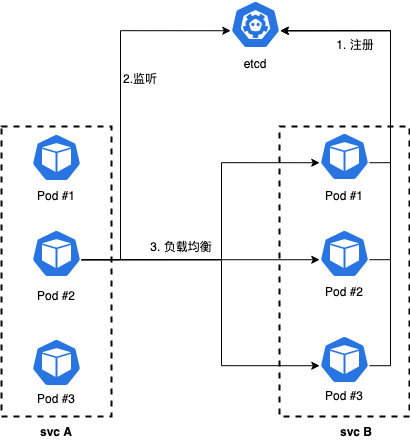
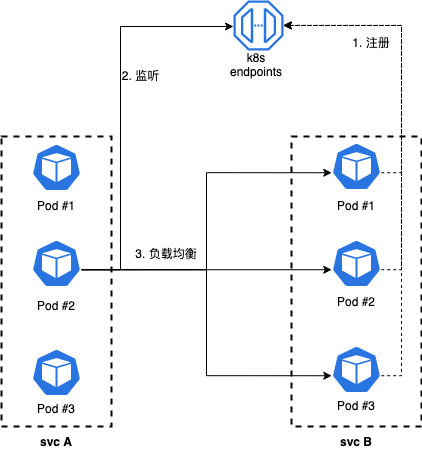
k8s service支持headless模式,创建service时,设置clusterip=none时,k8s将不再为servcie分配clusterip,即开启headless模式。headless service会将对应的每个 Pod IP 以 A 记录的形式存储。通过dsn lookup访问headless service时候,可以获取到所有Pod的IP信息。
# HELP go_gc_duration_seconds A summary of the GC invocation durations. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 3.5101e-05 # HELP go_goroutines Number of goroutines that currently exist. # TYPE go_goroutines gauge go_goroutines 6 ... process_open_fds 12 # HELP process_resident_memory_bytes Resident memory size in bytes. # TYPE process_resident_memory_bytes gauge process_resident_memory_bytes 1.1272192e+07 # HELP process_virtual_memory_bytes Virtual memory size in bytes. # TYPE process_virtual_memory_bytes gauge process_virtual_memory_bytes 4.74484736e+08
在初始化时,client_golang注册了 2 个 Prometheu 收集器:
进程收集器 —— 用于收集基本的 Linux 进程信息,比如 CPU、内存、文件描述符使用情况,以及启动时间等。
Go 收集器 —— 用于收集有关 Go 运行时的信息,比如 GC、gouroutine 和 OS 线程的数量的信息。
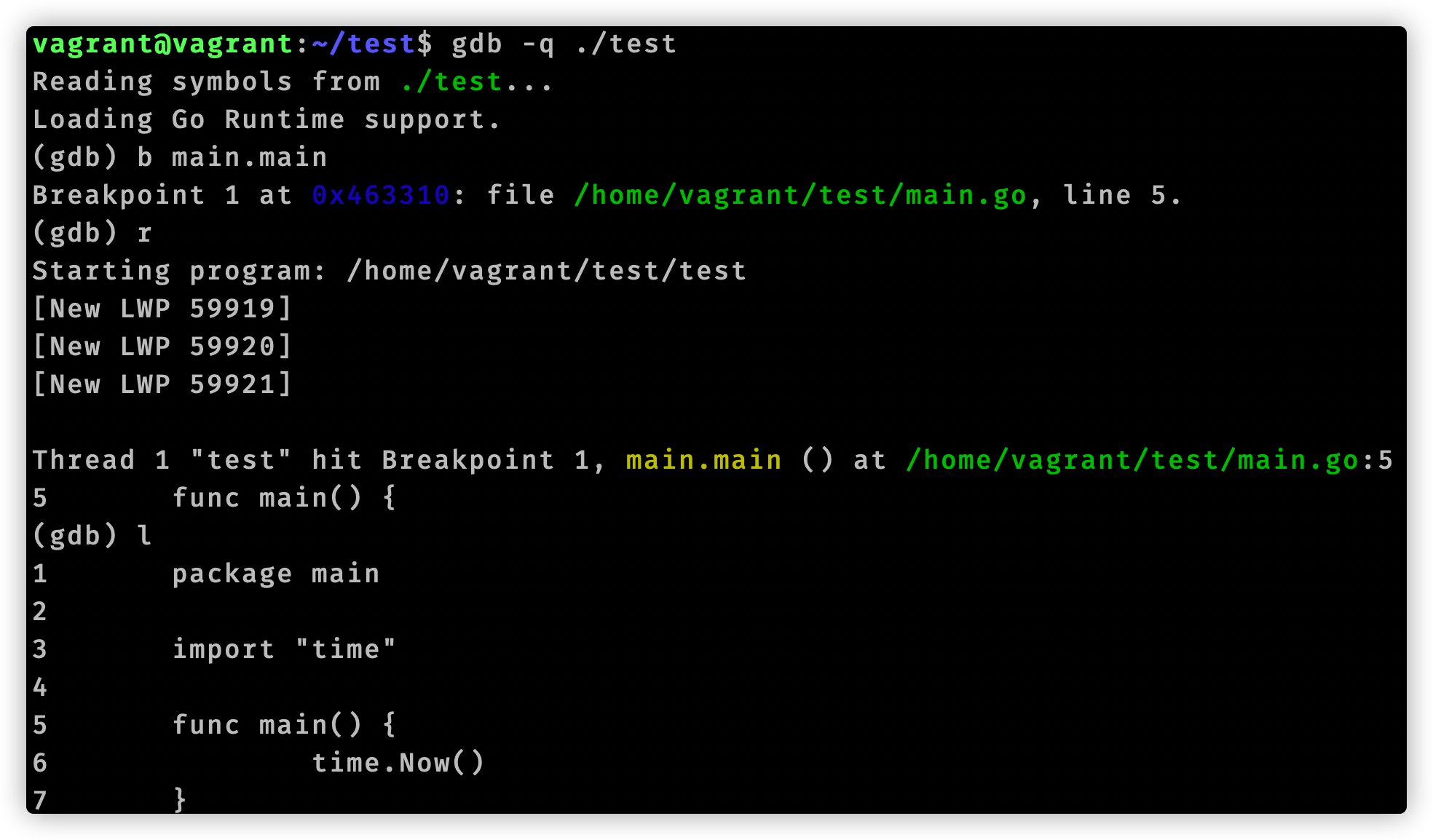
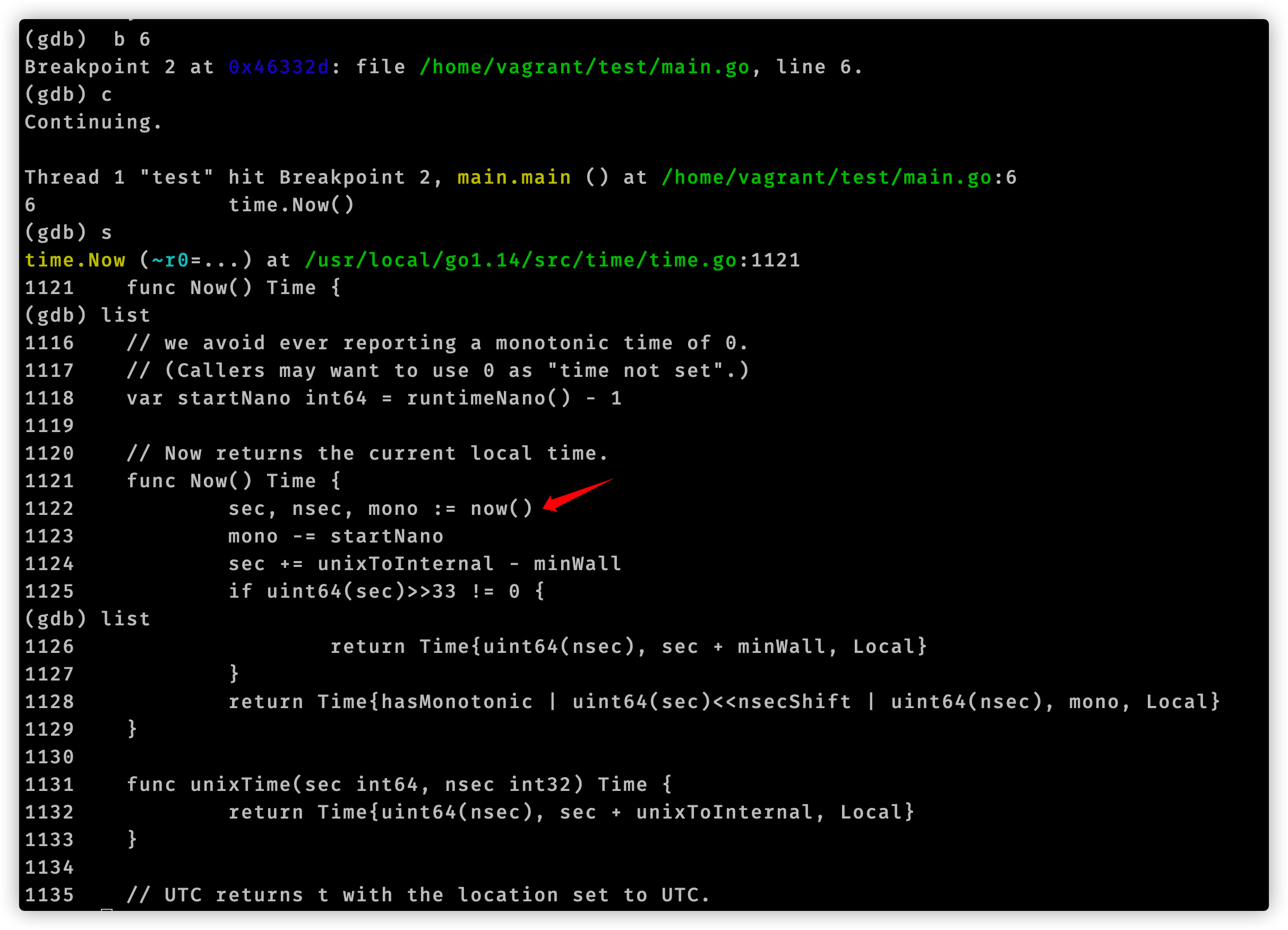
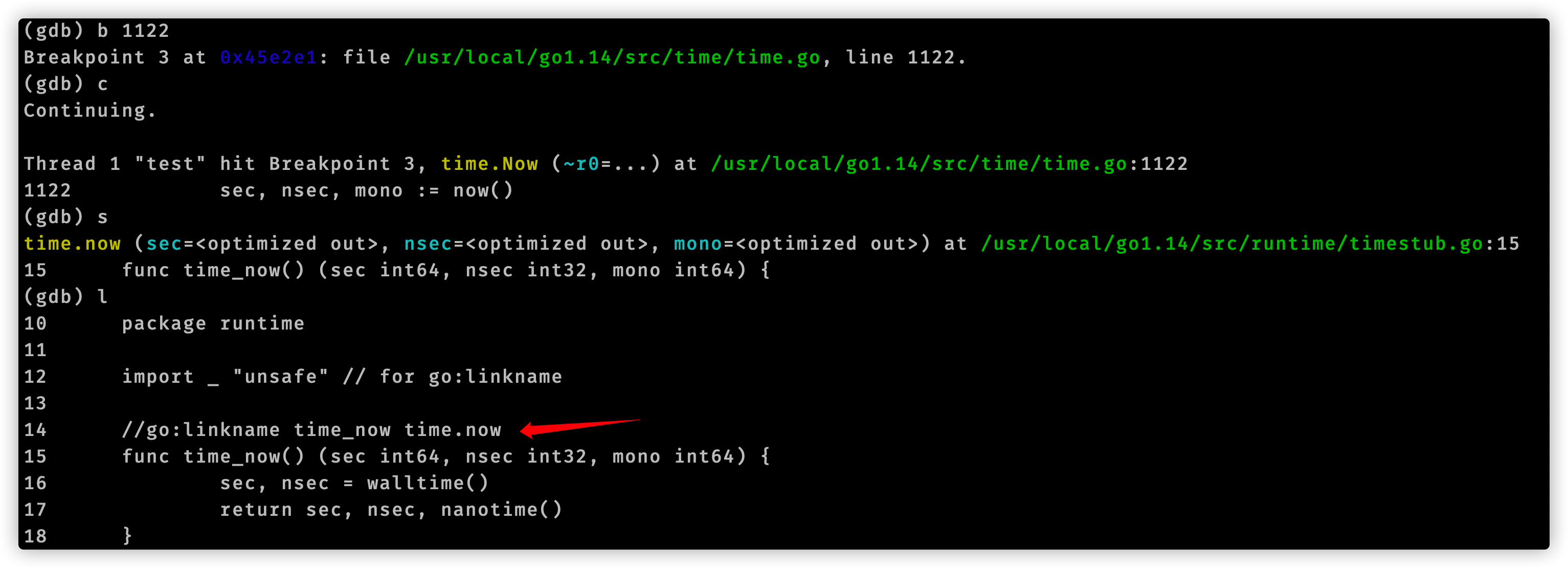
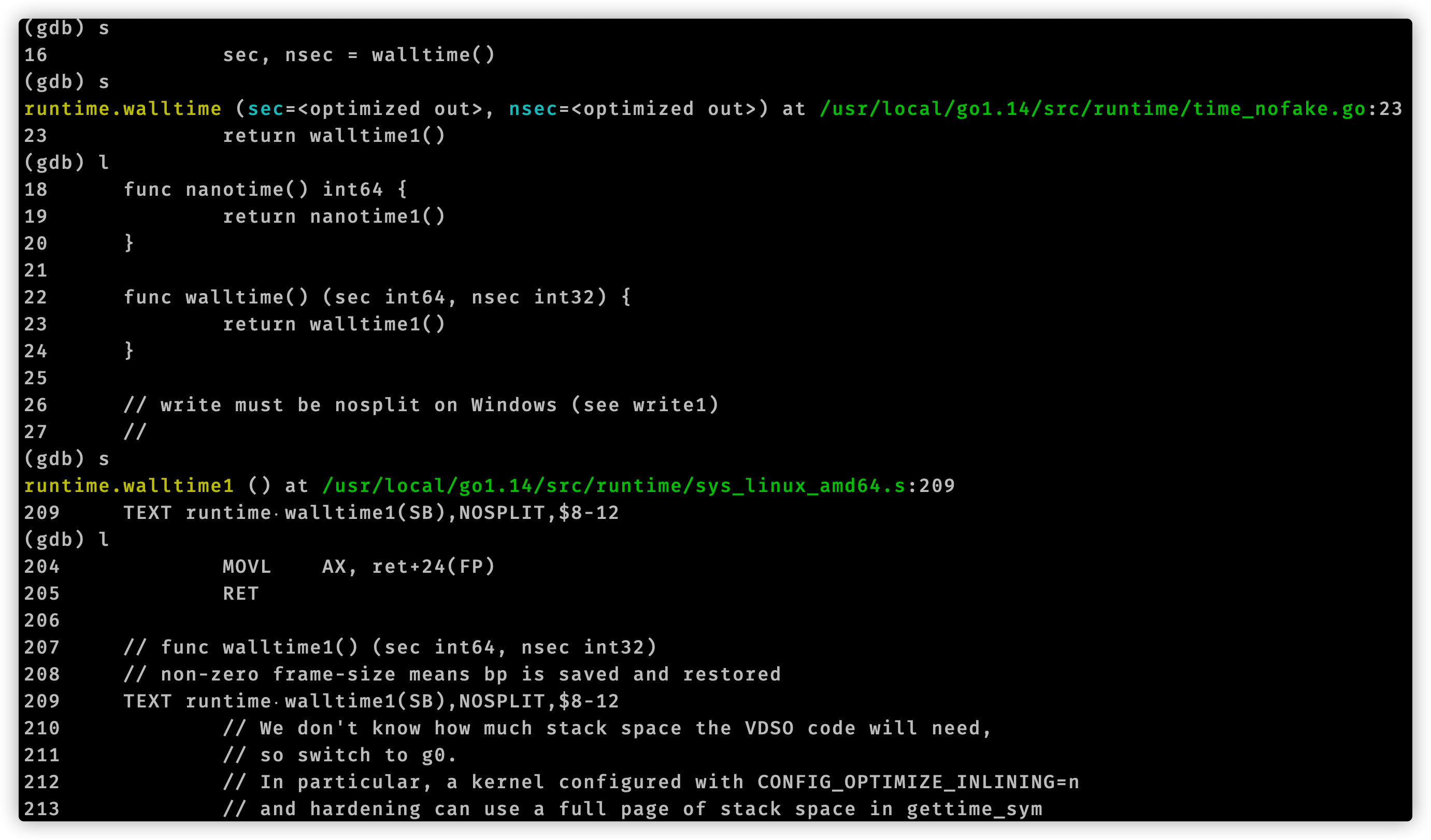
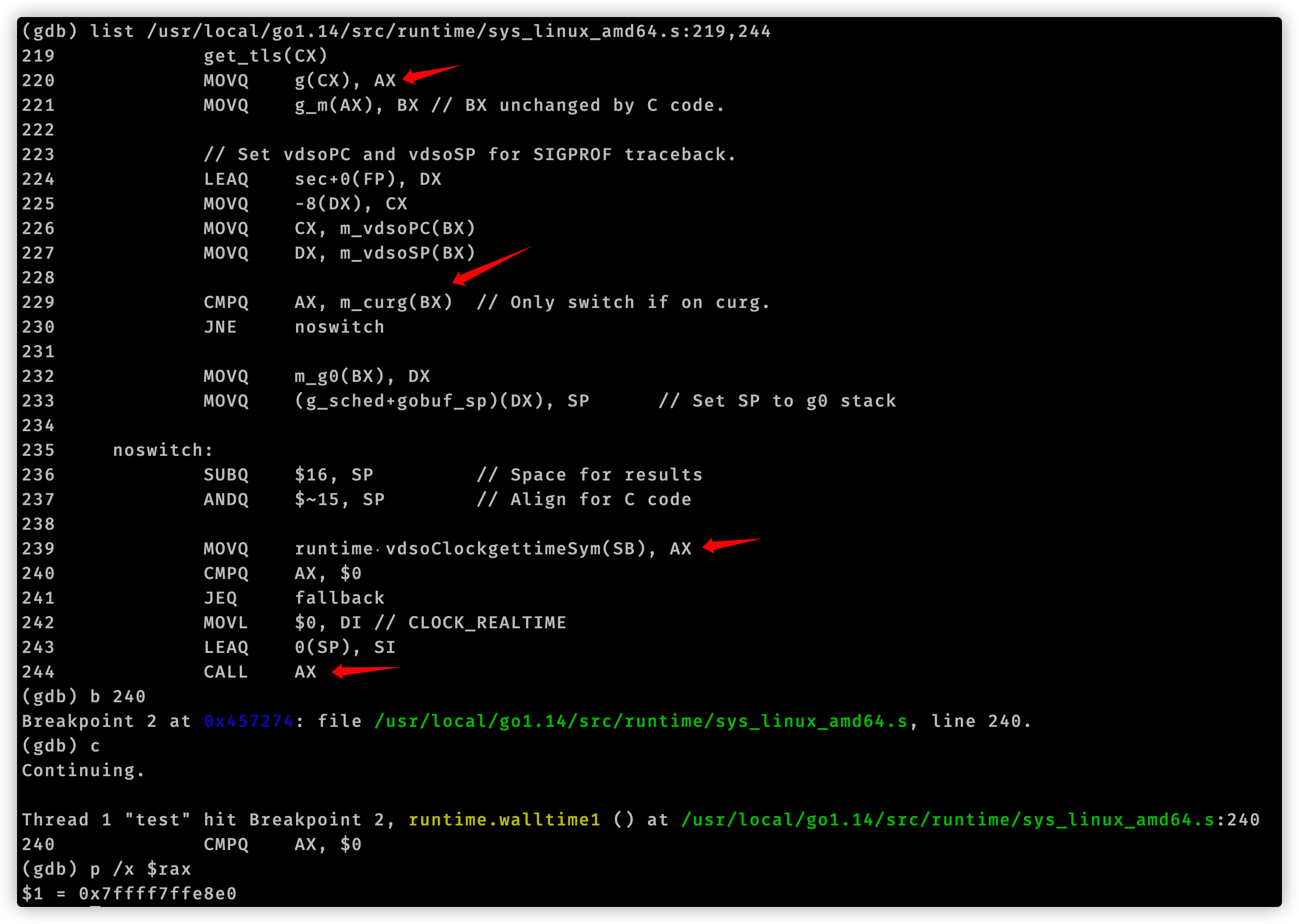
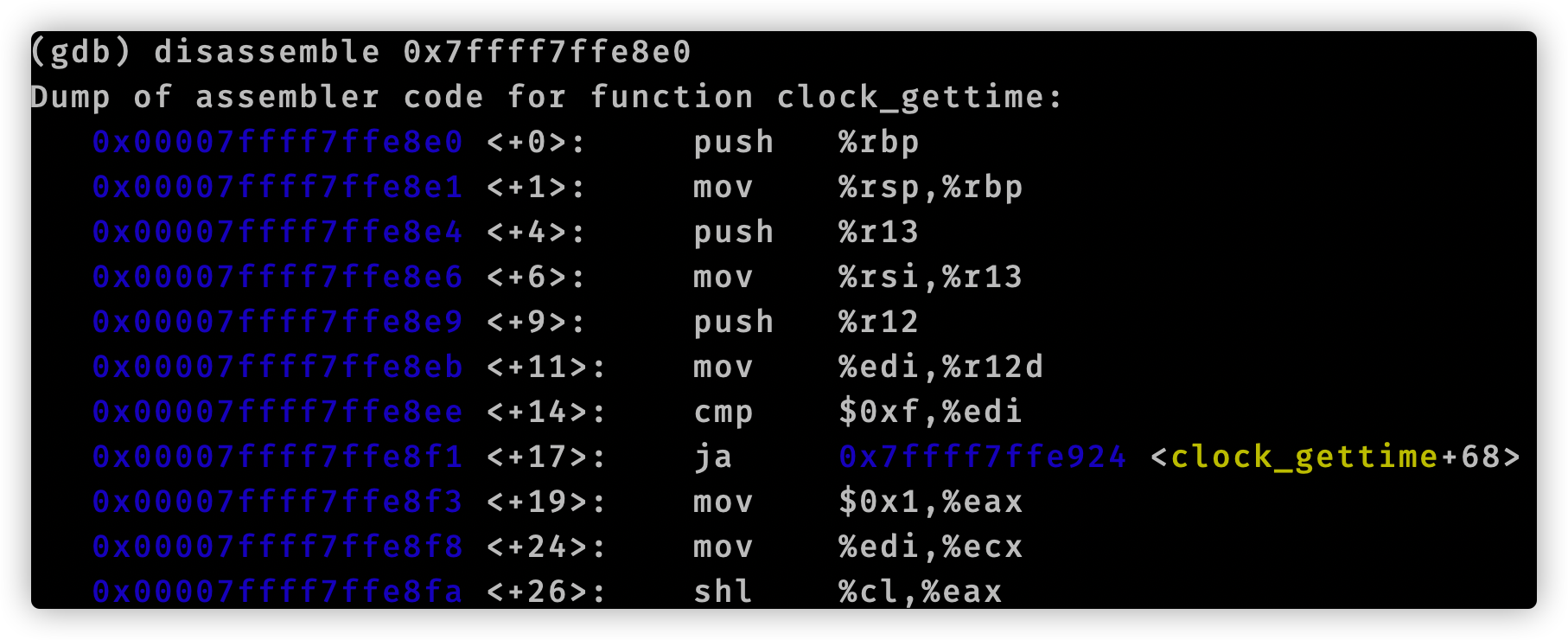
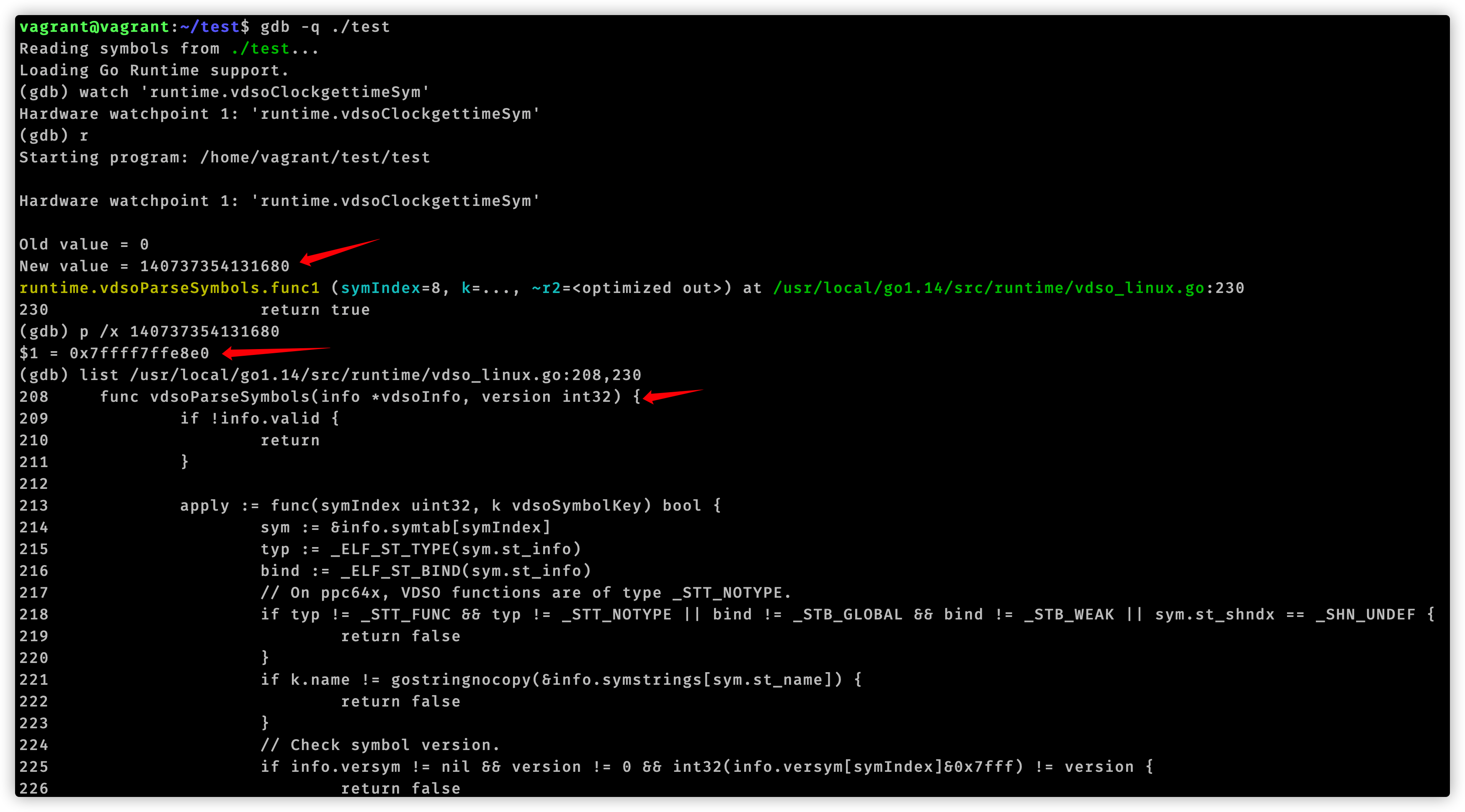
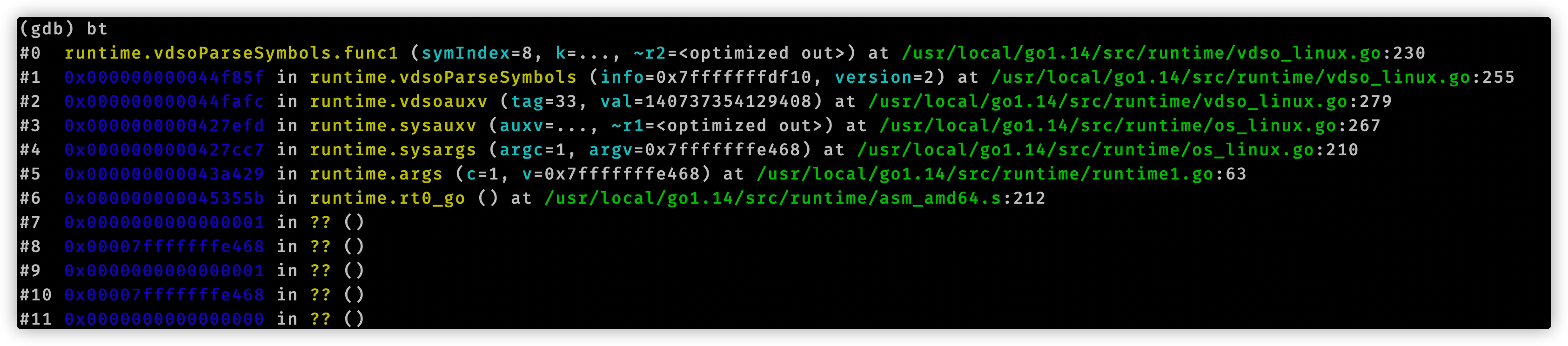
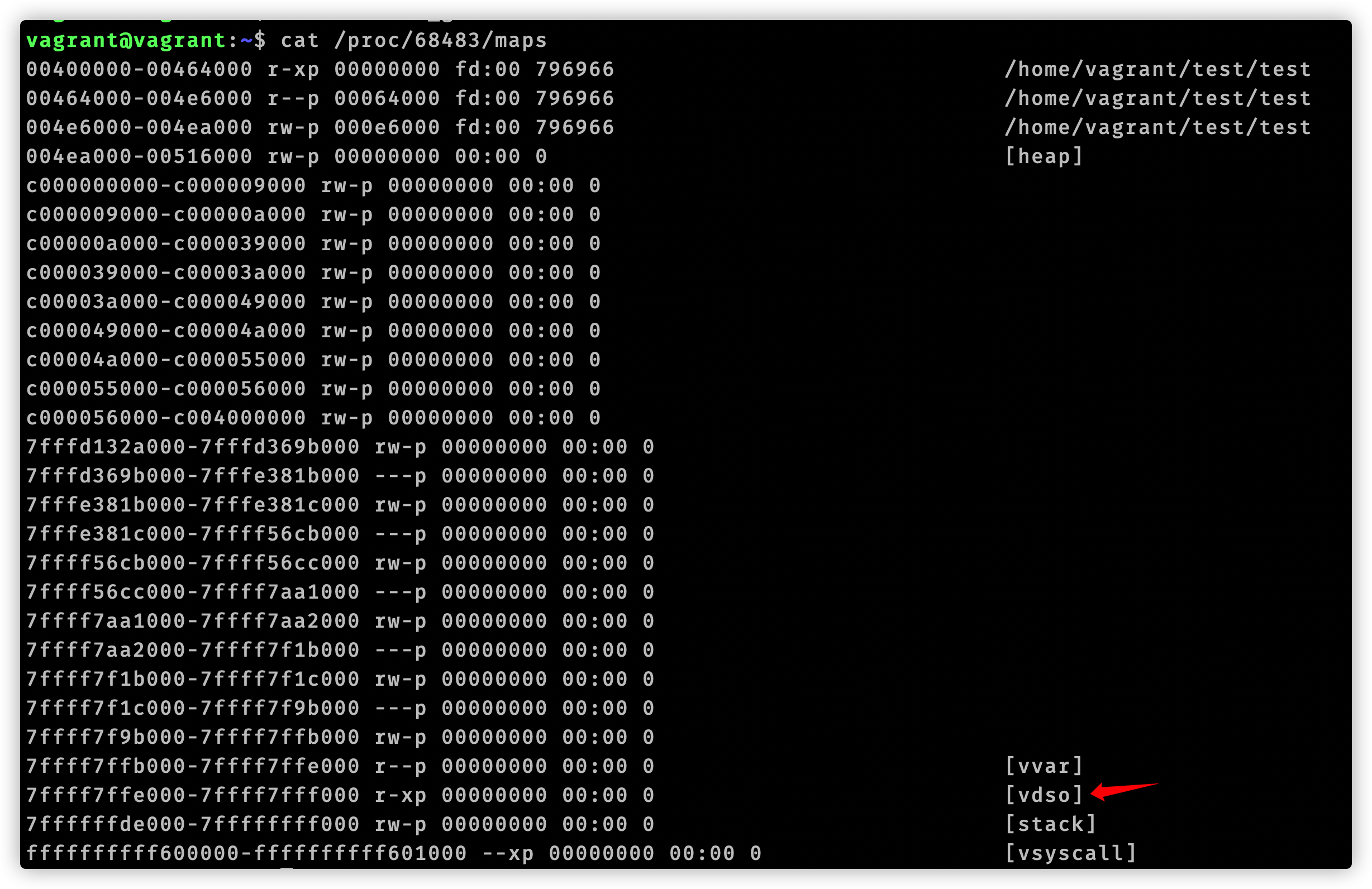
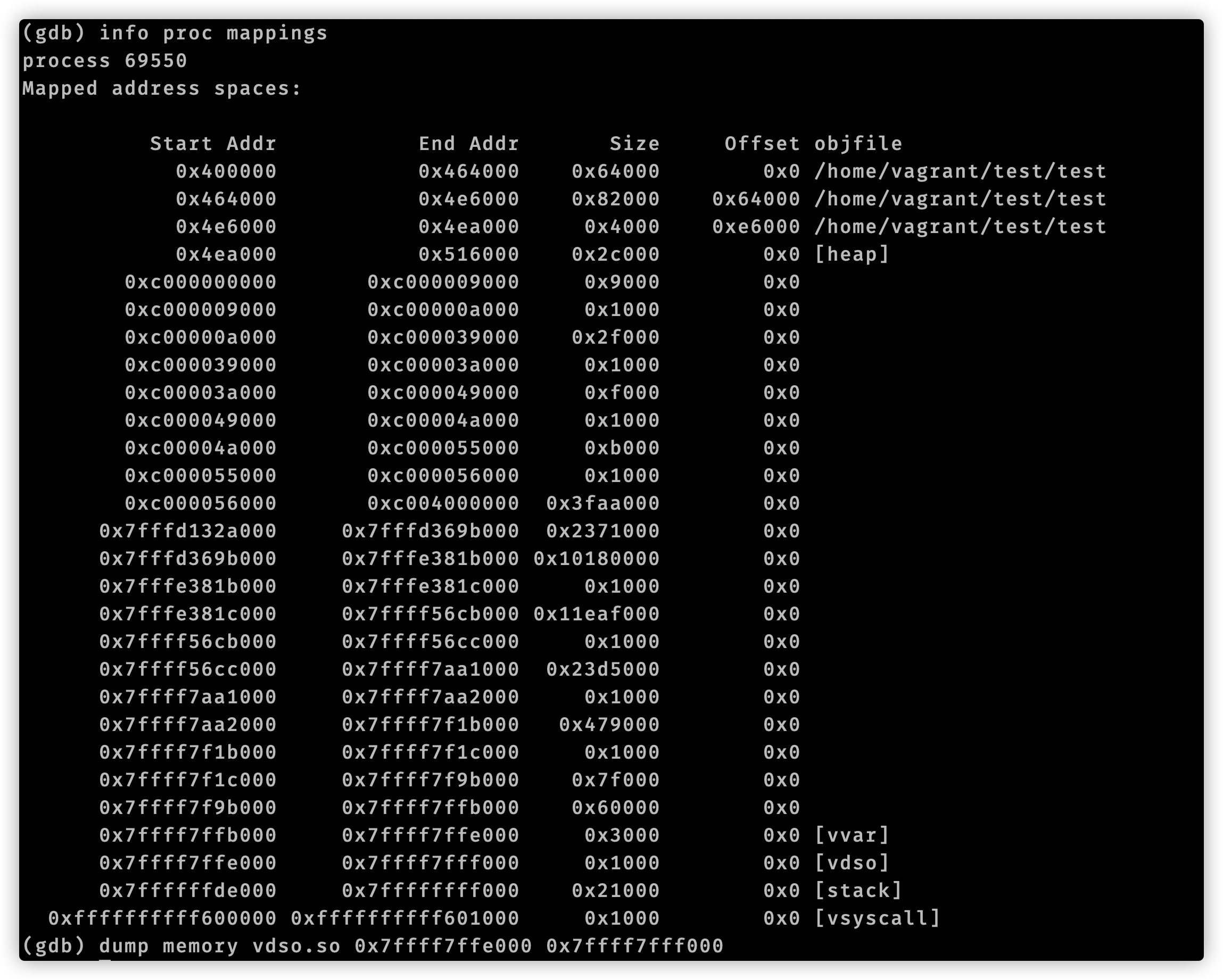
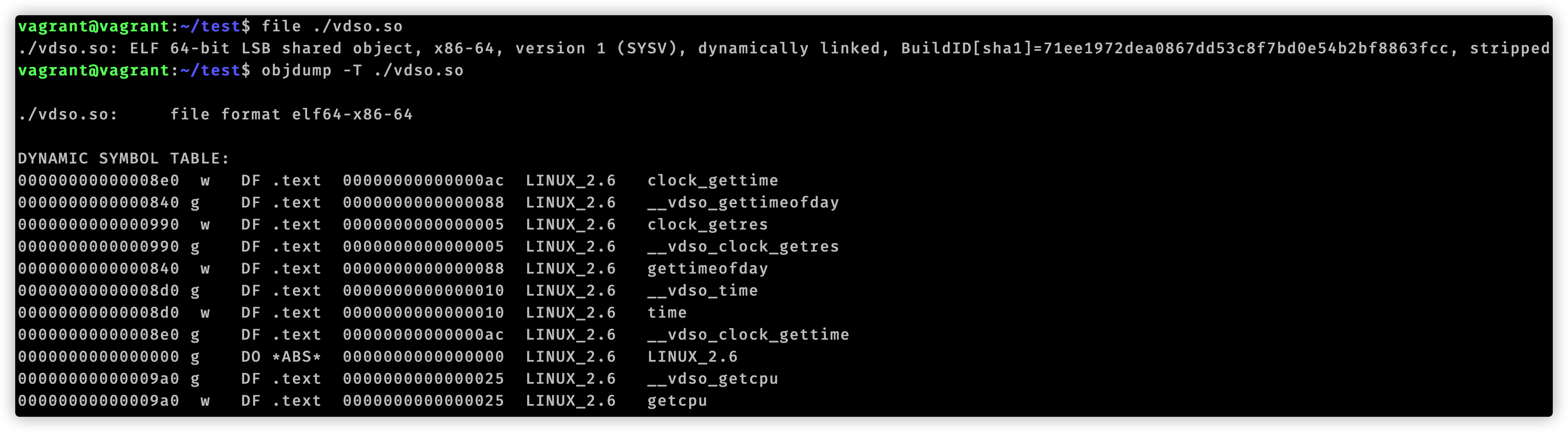
至此我们使用gdb分析追踪time.Now()结束了。我们用代码编辑器查看vdsoParseSymbols这个函数,它位于runtime/vdso_linux.go文件中。在这个文件开头注释有这么一句话:Look up symbols in the Linux vDSO.。结合函数名称,可以知道vdsoParseSymbols用来完成vDSO的符号解析。这就引入了vDSO概念。
funcvdsoauxv(tag, val uintptr) { switch tag { case _AT_SYSINFO_EHDR: if val == 0 { // Something went wrong return } var info vdsoInfo // TODO(rsc): I don't understand why the compiler thinks info escapes // when passed to the three functions below. info1 := (*vdsoInfo)(noescape(unsafe.Pointer(&info))) vdsoInitFromSysinfoEhdr(info1, (*elfEhdr)(unsafe.Pointer(val))) vdsoParseSymbols(info1, vdsoFindVersion(info1, &vdsoLinuxVersion)) } }
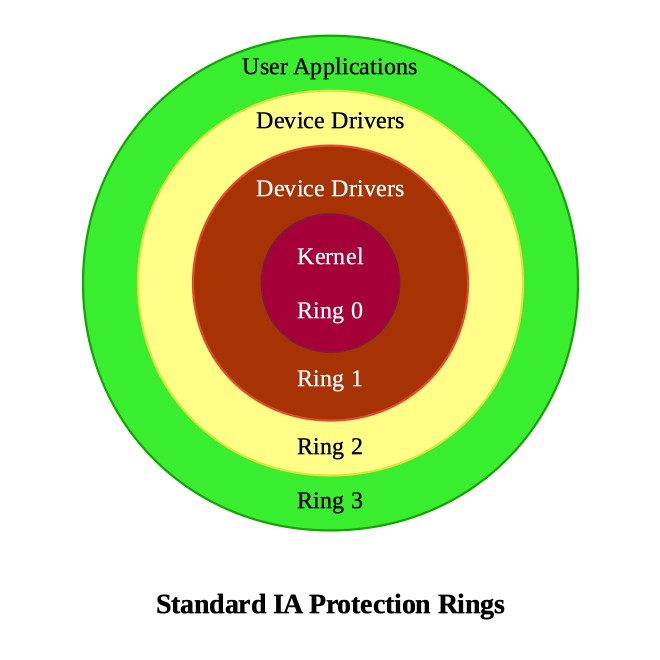
These functions require great care to be used correctly. Except for special, low-level applications, synchronization is better done with channels or the facilities of the sync package. Share memory by communicating; don’t communicate by sharing memory. 使用这些功能需要非常小心。除了特殊的底层应用程序外,最好使用通道或sync包来进行同步。通过通信来共享内存;不要通过共享内存来通信。
atomic包提供的操作可以分为三类:
对整数类型T的操作
T类型是int32、int64、uint32、uint64、uintptr其中一种。
1 2 3 4 5
funcAddT(addr *T, delta T)(new T) funcCompareAndSwapT(addr *T, old, new T)(swapped bool) funcLoadT(addr *T)(val T) funcStoreT(addr *T, val T) funcSwapT(addr *T, new T)(old T)
对于unsafe.Pointer类型的操作
1 2 3 4
funcCompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer)(swapped bool) funcLoadPointer(addr *unsafe.Pointer)(val unsafe.Pointer) funcStorePointer(addr *unsafe.Pointer, val unsafe.Pointer) funcSwapPointer(addr *unsafe.Pointer, new unsafe.Pointer)(old unsafe.Pointer)
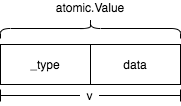
if typ != xp.typ { // 再次Store操作时进行typ类型校验,确保每次Store数据对象都必须是同一类型 panic("sync/atomic: store of inconsistently typed value into Value") } StorePointer(&vp.data, xp.data) // vp.data == xp.data return } }
func(v *Value)Load()(x interface{}) { vp := (*ifaceWords)(unsafe.Pointer(v)) // 将指向v指针转换成*ifaceWords类型 typ := LoadPointer(&vp.typ) if typ == nil || uintptr(typ) == ^uintptr(0) { // typ == nil 说明Store方法未调用过 // uintptr(typ) == ^uintptr(0) 说明第一Store方法调用正在进行中 returnnil } data := LoadPointer(&vp.data) xp := (*ifaceWords)(unsafe.Pointer(&x)) xp.typ = typ xp.data = data return }
]]><h2 id="atomic概述"><a class="markdownIt-Anchor" href="#atomic概述"></a> atomic概述</h2>
<p>atomic是Go内置原子操作包。下面是官方说明:</p>
<blockquote>
<p>Package atomic provides low-level atomic memory primitives useful for implementing synchronization algorithms. atomic包提供了用于实现同步机制的底层原子内存原语。</p>
</blockquote>
<blockquote>
<p>These functions require great care to be used correctly. Except for special, low-level applications, synchronization is better done with channels or the facilities of the sync package. Share memory by communicating; don’t communicate by sharing memory. 使用这些功能需要非常小心。除了特殊的底层应用程序外,最好使用通道或sync包来进行同步。<strong>通过通信来共享内存;不要通过共享内存来通信</strong>。</p>
</blockquote>这可能是你最想要的一份GDB使用指南http://www.cyub.vip/2021/03/22/%E8%BF%99%E5%8F%AF%E8%83%BD%E6%98%AF%E4%BD%A0%E6%9C%80%E6%83%B3%E8%A6%81%E7%9A%84%E4%B8%80%E4%BB%BDGDB%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97/2021-03-22T11:28:00.000Z2023-04-14T13:25:14.834Z GDB简介
(gdb) where #0 _rt0_amd64 () at /usr/lib/go/src/runtime/asm_amd64.s:15 #1 0x0000000000000001 in ?? () #2 0x00007fffffffdd2c in ?? () #3 0x0000000000000000 in ?? ()
func(e *entry)tryStore(i *interface{})bool { for { p := atomic.LoadPointer(&e.p) if p == expunged { returnfalse } if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) { returntrue } } }
func(m *Map)dirtyLocked() { if m.dirty != nil { return }
read, _ := m.read.Load().(readOnly) m.dirty = make(map[interface{}]*entry, len(read.m)) for k, e := range read.m { if !e.tryExpungeLocked() { m.dirty[k] = e } } }
func(e *entry)tryExpungeLocked()(isExpunged bool) { p := atomic.LoadPointer(&e.p) for p == nil { if atomic.CompareAndSwapPointer(&e.p, nil, expunged) { returntrue } p = atomic.LoadPointer(&e.p) } return p == expunged }