最近读了《Operating Systems: Three Easy Pieces》一书,全书主要围绕虚拟化、并发和持久化这三个主题展开,其中并发部分中介绍锁的章节,行文风趣幽默,写得非常精彩。文中介绍了多种实现锁的方案,以及各种锁的适用场景和优缺点。本文基于该书中锁章节,以一个gopher的角度去分享、拓展书中介绍的锁,并尽量使用Go实现书中介绍的几款自旋锁。
锁的基本思想
锁(lock)的目的是给临界区(Critical Section)加上一层保护,以保证临界区中代码能够像单条原子指令一样执行。临界区指的是一个访问共享资源的程序片段,比如对全局变量的访问、更新。在Linux系统中保护临界区的机制除了锁之外,还有信号量,屏障,RCU等手段。
锁本质是一个变量,我们通过lock()和unlock()这两个语义函数来操作锁变量。当线程准备进入临界区时候,会调用lock()尝试获取锁,当该锁状态是未上锁状态时候,线程会成功获取到锁,从而进入到临界区,如果此时其他线程尝试获取锁而进入临界区,会阻塞或者自旋。获取锁并进入临界区的线程称为锁的持有者,当锁持有者退出临界区时候,调用unlock()来释放锁,那么阻塞等待的其他线程继续开始竞争这个锁。下面是获取锁和释放锁的代码示例:
1 | lock_t mutex; |
忙等待 or 休眠阻塞
忙等待(Busy waiting),也称为自旋(Spin)或忙循环(busy looping),是一种同步技术,指的是线程在继续执行之前等待并不断检查要满足的条件。在忙等待中,线程执行指令以测试进入条件是否为真。
通过忙等待技术可以实现锁。当线程尝试将锁状态设置为上锁状态,如果成功,则该线程成为锁的持有者,其他线程不停自旋检查锁的状态,等待锁状态变成未上锁状态。通过忙等待实现的锁一般称为自旋锁(spin lock) 。自旋锁不会像POSIX库中的mutex锁陷入内核状态带来的性能损耗,但它不是银弹。比如对应单核操作系统,我们应该避免自旋处理,应该尽管让出CPU资源,比如单核操作系统自旋是没有意义的。在Go的 sync.Mutex 和 runtime.mutex 代码中可以看到这一点。
当临界区或者资源已被其他线程持有,除了自旋锁的忙等待外,还可以进行阻塞休眠,其他线程都休眠在一个队列上,等待资源被释放出来,休眠往往需要内核支持,这意味会发生上下文切换和线程切换。POSIX库中的mutex锁就是这样,当锁被持有了,其他线程就会休眠等待唤醒。
锁的评估标准
如何评价锁的好与坏,可以从下面三个指标考虑:
- 提供互斥(mutual exclusion) :这是最基本的要求。锁应该阻止多个线程同时进入临界区。对应Go之类支持coroutine语言就是阻止多个coroutine同时进入临界区。
- 公平性(fairness) :每一个竞争的线程是否有公平的机会抢到锁机会?也就是说不能出现线程一直获取不到锁的,导致饿死(starve)的情况
- 性能(performance) :指的是使用锁之后增加的时间开销,越少越好,需要考虑这些场景:
- 没有竞争的情况下,即只有一个线程抢锁、释放锁的开支如何?
- 一个CPU上多个线程竞争,性能如何?
- 多个CPU、多个线程竞争时的性能?
POSIX中的互斥量
POSIX库中将锁称为互斥量(英文单词是mutex,是互斥MUTual EXclusion一词的缩写),用来提供线程之间的互斥,即当一个线程在临界区时,它能够阻止其他线程进入直到本线程离开临界区。
1 | pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER; // pthread = posix + thread |
我们可以通过下面代码验证下使用mutex与未使用mutex的情况:
1 |
|
我们在编译时候添加-fsanitize=thread选项,开启Data race检测功能。接着运行编译后的程序,会看到下面的信息。我们可以看到sum1的赋值操作存在竞态,而使用了mutex的sum2没有:
1 | ubuntu@VM-0-3-ubuntu:/tmp/lock$ gcc -fsanitize=thread -g main.c -o sum.out |
gcc编译时候-fsanitize=thread选项使用的是ThreadSanitizer,Go语言中竞态检查的-race选项也是基于此实现的。
锁的实现
中断指令
在最早期,那时候还是单核处理器系统时候,锁的实现比较简单:在进入临界区之前使用硬件指令关闭中断,保证临界区的代码执行时不会被中断,从而原子地执行。当临界区结束之后,使用打开中断的硬件指令开启中断。伪代码如下:
1 | void lock() { |
通过中断指令实现锁的效率很差,因为中断指令是非常耗时的,更糟糕的是恶意程序可以通过不停调用lock()来阻止系统获取控制权。随着处理器的发展,提供了更多了硬件原子指令,聪明的开发者基于各种各样的硬件原语,在软硬件协同之上实现了多种锁。下面将介绍测试并设置、测试测试并设置、获取并增加、比较并交换等原语等实现的锁。
测试并设置
测试并设置(test-and-set) 原理是用一个变量来标志锁是否被某些线程占用。第一个线程进入临界区,调用 lock(),检查标志是否为1,如果不是1,将标志设置为1,表明线程持有该锁。结束临界区时,线程调用 unlock(),清除标志,表示锁未被持有。使用C语言实现的测试并设置锁的伪代码如下:
1 | typedef struct lock_t { int flag; } lock_t; |
测试并设置可以通过 xchg 指令实现,下面是Plan 9汇编代码实现lock()的代码:
1 | TEXT ·TestAndSetLock(SB), NOSPLIT, $0-8 |
Plan 9汇编是Go语言中使用的汇编,语法规则可以参考官方指南:A Quick Guide to Go’s Assembler。Go中atomic包提供了类似SwapXX的原子操作,我们可以使用其实现测试并设置锁:
1 | func (l *testAndSetLock) Lock() { |
测试测试并设置
在使用测试并设置机制实现锁的时候,使用到了 xchg 指令,该指令会隐式发送lock前缀信号来强制CPU会锁住缓存行或者总线(当数据不在缓存里面会锁住总线)从而使实现原子操作。当锁状态是1时候,一定能保证其他线程读取的状态值也是1,我们可以在xchg 指令值前读取该状态是不是1,来决定下一步操作,以避免锁缓存,这种机制称为测试测试并设置(test-test-and-set) 。Plan 9汇编代码实现lock的代码如下所示:
1 | TEXT ·TestAndTestAndSetLock(SB), NOSPLIT, $0-8 |
Go实现的核心代码如下,感兴趣的可以对比下test-and-set和test-test-and-set性能基准测试的结果:
1 | func (l *testAndTestAndSetLock) Lock() { |
获取并增加
获取并增加(fetch-and-add) 指的是原子地把值加一,并返回该值之前的值。在x86架构CPU中,可以使用的 xadd 指令实现,需要注意的是xadd指令需要加上lock前缀指令,保证原子性:
1 | TEXT ·FetchAndAdd(SB), NOSPLIT, $0-24 |
基于该硬件原语我们可以实现一款排队形式的排号自旋锁(ticket lock),下面是该锁C语言实现的伪代码:
1 | int FetchAndAdd(int *ptr) { |
上面代码中使用ticket字段记录全局票号,turn字段记录当前可以进入临界区的票号,当线程尝试进入临界区时候,会通过fetch-and-add原语获取自己的票号mytrun,并将全局票号ticket增一,通过比较线程自己的票号mytrun和临界区允许的进入票号trun,相同则允许进入,否则自旋或者阻塞。当ticket锁持有者退出临界区时候,会将trun加一,这类似点餐时候的叫号,叫下一位取餐者。
从上面解释中可以看到ticket锁是完全公平的,每一个尝试进入临界区的线程都有拥有自己票号,最终一定也会排到自己进入临界区。绝对的公平,往往却是不是最高效的。因为ticket锁中每一个线程都拥有了自己的票号,然后不停去询问自己的票号是不是当前允许进入临界区的票号,而系统中只能有一个线程才能进入临界区,也就是说只有持有临界区票号的线程的询问才是有效询问,其他都是无效的(不持有临界区票号的线程去询问,问了也是白问)。
ticket性能相对比较差,从底层分析来看,是因为每个CPU自旋在相同ticket上,根据cache一致性协议,如果ticket值更改之后,其他CPU上的cache line会变成invalidate状态,它们必须重新从内存中读取ticket值,这个过程效率比较低效。如果每个尝试获取线程都有自己的局部变量上面自旋就可以避免ticket这个问题,这个也是下面将要介绍的mcs锁的实现思路。
下面我们来看看Go语言中如何实现ticket锁。Go语言中atomic.AddXX使用了xadd指令,可惜的是返回最新的值,而不是旧值。我们可以atomic.CompareAndSwapXX来实现fetch-and-add原语,核心代码如下:
1 | func (l *fetchAndAddLock) Lock() { |
Mcs锁
Mcs锁是根据发明人John Mellor-Crummey和Michael Scott的名字命名的。linux内核中实现了Mcs锁,它的结构如下所示, 其中next指向下一个msc_spinlock,locked标志是否获取到锁:
1 | struct mcs_spinlock { |
Mcs锁实现的思路是每一个线程都有一个自己的mcs_spinlock,当尝试获取锁时候,会将其原子交换操作链接到next字段构成的链表中,如果返回的前一个mcs_spinlock为空,则说明此时锁是free的,则该线程获取到锁。若前一个msc_spinlock不为空,则将当前线程的mcs_spinlock挂载到前一个msc_spinlock的next上,该线程会自旋在自己的mcs_spinlock的locked字段,等待locked变为1。 当锁持有者释放锁时候,会将其msc_spinlock指向的next中locked置为1。
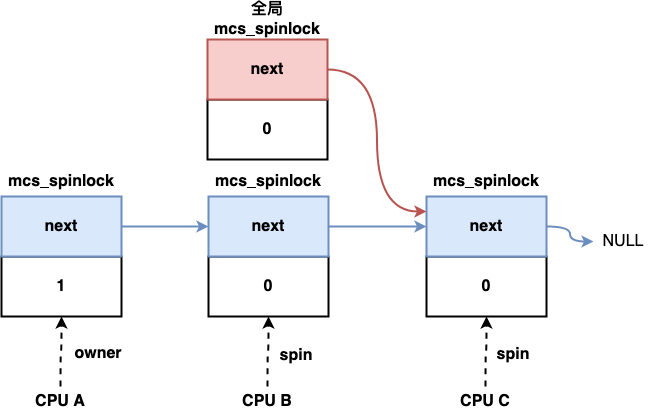
Mcs锁可以利用到缓存局部性,每个线程自旋在自己的状态变量(locked字段)上,但其使用上不太友好,上锁和释放锁时都需要传递自己的锁结构。下面是Go实现的Mcs锁的核心代码:
1 | type mscLock struct { |
同ticket锁一样,Mcs锁也是排号自旋锁,遵循了 FCFS 原则(先来先服务原则),是公平锁。Mcs锁避免了ticket锁缓存失效重新读取内存的问题,理论上性能会比ticket锁好。需要注意的是本文描述的锁是在线程模型(内核级线程模型)下,而Go调度最小单元是协程,属于混合型线程模型,锁的实际性能可能跟预期不一致。
比较并交换
比较并交换(compare-and-swap,简称cas) 是另外一个硬件原语,x86架构CPU对应的指令是 cmpxchg,下面是该指令实现的功能,用C语言表达的伪代码:
1 | int CompareAndSwap(int *ptr, int expected, int new) { |
基于比较并交换实现的锁的C语言伪代码如下:
1 | void lock(lock_t *lock) { |
在实际项目中基于比较交换原语实现自旋锁是较多的方案。Go里面atomic提供了CAS的原子操作,我们可以基于此实现一款自旋锁。
1 | func (l *casLock) Lock() { |
两阶段锁
两阶段锁指在获取锁的时候,分为两阶段处理:第一阶段会先自旋一段时间,希望它可以获取锁。如果第一个自旋阶段没有获得锁,则会睡眠,直到锁可用。两阶段锁避免了自旋锁一直自旋带来的CPU的无效浪费,另外第一阶段先自旋一段时间,而不是在未成功获取锁时直接休眠,这样可以减少上下文切换的性能损耗。在Go语言中 sync.Mutex 设计上也采用了该思路:
1 | func (m *Mutex) lockSlow() { |
读者-写者问题
读者-写者问题(Readers–writers problem)描述的是多个线程(进程)之间共享资源的问题,其中一些线程是读者,即他们想读取共享资源,而一些线程是写者,即他们想写入数据到共享资源。解决读者-写者问题可以使用上面介绍的自旋锁,它对读者,写者一视同仁,当其中一方获取到锁之后,其他方只能等待锁释放。