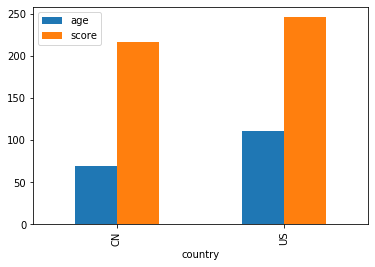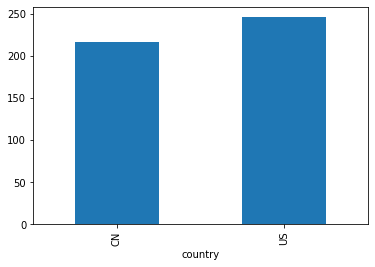Pandas 是一个Python语言实现的,开源,易于使用的数据架构以及数据分析工具。在Pandas中主要有两种数据类型,可以简单的理解为:
Series:一维数组(列表)
DateFrame:二维数组(矩阵)
在线实验:Pandas完全指南.ipynb
学习资料:
1 2 3 import pandas as pdimport numpy as npfrom IPython.display import Image
1 s = pd.Series([1 , 3 , 6 , np.nan, 23 , 3 ])
1 dates = pd.date_range('20200101' , periods=6 )
1 df = pd.DataFrame(np.random.randn(6 , 4 ), index=dates, columns=['a' , 'b' , 'c' , 'd' ])
a b c d 2020-01-01 -1.365774 1.169899 0.607591 -2.029687 2020-01-02 -0.967683 -0.800448 0.123673 0.700337 2020-01-03 1.790609 0.560666 0.344051 0.799520 2020-01-04 2.068663 0.320610 -1.660631 0.416631 2020-01-05 -0.956351 -0.657050 1.241433 -0.652496 2020-01-06 -1.135870 1.888093 0.533364 0.080852
1 2 3 4 5 df2 = pd.DataFrame({ 'a' :pd.Series([1 , 2 , 3 , 4 ]), 'b' :pd.Timestamp('20180708' ), 'c' :pd.Categorical(['cate1' , 'cate2' , 'cate3' , 'cate4' ]) })
a b c 0 1 2018-07-08 cate1 1 2 2018-07-08 cate2 2 3 2018-07-08 cate3 3 4 2018-07-08 cate4
1 2 3 4 5 6 7 data = {'name' : ['Jason' , 'Molly' , 'Tina' , 'Jake' , 'Amy' , 'Jack' , 'Tim' ], 'age' : [20 , 32 , 36 , 24 , 23 , 18 , 27 ], 'gender' : np.random.choice(['M' ,'F' ],size=7 ), 'score' : [25 , 94 , 57 , 62 , 70 , 88 , 67 ], 'country' : np.random.choice(['US' ,'CN' ],size=7 ), } df3 = pd.DataFrame(data, columns = ['name' , 'age' , 'gender' , 'score' , 'country' ])
name age gender score country 0 Jason 20 F 25 US 1 Molly 32 F 94 US 2 Tina 36 F 57 US 3 Jake 24 M 62 CN 4 Amy 23 F 70 US 5 Jack 18 M 88 CN 6 Tim 27 F 67 CN
(6, 4)
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06'],
dtype='datetime64[ns]', freq='D')
Index(['a', 'b', 'c', 'd'], dtype='object')
array([[-1.36577441, 1.16989918, 0.60759059, -2.02968684],
[-0.96768326, -0.80044798, 0.12367311, 0.70033731],
[ 1.79060939, 0.56066552, 0.34405077, 0.79952019],
[ 2.06866329, 0.32060998, -1.6606308 , 0.41663058],
[-0.95635134, -0.65704975, 1.24143335, -0.65249624],
[-1.1358703 , 1.88809265, 0.53336403, 0.08085195]])
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 6 entries, 2020-01-01 to 2020-01-06
Freq: D
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 a 6 non-null float64
1 b 6 non-null float64
2 c 6 non-null float64
3 d 6 non-null float64
dtypes: float64(4)
memory usage: 240.0 bytes
a b c d count 6.000000 6.000000 6.000000 6.000000 mean -0.094401 0.413628 0.198247 -0.114141 std 1.577260 1.038903 0.984921 1.074899 min -1.365774 -0.800448 -1.660631 -2.029687 25% -1.093824 -0.412635 0.178768 -0.469159 50% -0.962017 0.440638 0.438707 0.248741 75% 1.103869 1.017591 0.589034 0.629411 max 2.068663 1.888093 1.241433 0.799520
1 2 3 4 df.index = pd.date_range('2020/06/01' , periods=df.shape[0 ]) df
a b c d 2020-06-01 -1.365774 1.169899 0.607591 -2.029687 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 2020-06-03 1.790609 0.560666 0.344051 0.799520 2020-06-04 2.068663 0.320610 -1.660631 0.416631 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 2020-06-06 -1.135870 1.888093 0.533364 0.080852
a b c d 2020-06-01 -1.365774 1.169899 0.607591 -2.029687
a b c d 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 2020-06-03 1.790609 0.560666 0.344051 0.799520 2020-06-04 2.068663 0.320610 -1.660631 0.416631 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 2020-06-06 -1.135870 1.888093 0.533364 0.080852
1 df['a' ].value_counts(dropna=False )
1.790609 1
-1.135870 1
2.068663 1
-0.967683 1
-1.365774 1
-0.956351 1
Name: a, dtype: int64
1 df.apply(pd.Series.value_counts)
a b c d -2.029687 NaN NaN NaN 1.0 -1.660631 NaN NaN 1.0 NaN -1.365774 1.0 NaN NaN NaN -1.135870 1.0 NaN NaN NaN -0.967683 1.0 NaN NaN NaN -0.956351 1.0 NaN NaN NaN -0.800448 NaN 1.0 NaN NaN -0.657050 NaN 1.0 NaN NaN -0.652496 NaN NaN NaN 1.0 0.080852 NaN NaN NaN 1.0 0.123673 NaN NaN 1.0 NaN 0.320610 NaN 1.0 NaN NaN 0.344051 NaN NaN 1.0 NaN 0.416631 NaN NaN NaN 1.0 0.533364 NaN NaN 1.0 NaN 0.560666 NaN 1.0 NaN NaN 0.607591 NaN NaN 1.0 NaN 0.700337 NaN NaN NaN 1.0 0.799520 NaN NaN NaN 1.0 1.169899 NaN 1.0 NaN NaN 1.241433 NaN NaN 1.0 NaN 1.790609 1.0 NaN NaN NaN 1.888093 NaN 1.0 NaN NaN 2.068663 1.0 NaN NaN NaN
1 2 3 df.sort_index(axis=0 , ascending=False )
a b c d 2020-06-06 -1.135870 1.888093 0.533364 0.080852 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 2020-06-04 2.068663 0.320610 -1.660631 0.416631 2020-06-03 1.790609 0.560666 0.344051 0.799520 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 2020-06-01 -1.365774 1.169899 0.607591 -2.029687
1 df.sort_index(axis=1 , ascending=False )
d c b a 2020-06-01 -2.029687 0.607591 1.169899 -1.365774 2020-06-02 0.700337 0.123673 -0.800448 -0.967683 2020-06-03 0.799520 0.344051 0.560666 1.790609 2020-06-04 0.416631 -1.660631 0.320610 2.068663 2020-06-05 -0.652496 1.241433 -0.657050 -0.956351 2020-06-06 0.080852 0.533364 1.888093 -1.135870
1 df.sort_values(by='a' , ascending=False )
a b c d 2020-06-04 2.068663 0.320610 -1.660631 0.416631 2020-06-03 1.790609 0.560666 0.344051 0.799520 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 2020-06-06 -1.135870 1.888093 0.533364 0.080852 2020-06-01 -1.365774 1.169899 0.607591 -2.029687
1 df.sort_values(by=['a' ,'b' ], ascending=True )
a b c d 2020-06-01 -1.365774 1.169899 0.607591 -2.029687 2020-06-06 -1.135870 1.888093 0.533364 0.080852 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 2020-06-03 1.790609 0.560666 0.344051 0.799520 2020-06-04 2.068663 0.320610 -1.660631 0.416631
2020-06-01 -1.365774
2020-06-02 -0.967683
2020-06-03 1.790609
2020-06-04 2.068663
2020-06-05 -0.956351
2020-06-06 -1.135870
Freq: D, Name: a, dtype: float64
1 df['2020-06-01' :'2020-06-02' ]
a b c d 2020-06-01 -1.365774 1.169899 0.607591 -2.029687 2020-06-02 -0.967683 -0.800448 0.123673 0.700337
c b 2020-06-01 0.607591 1.169899 2020-06-02 0.123673 -0.800448 2020-06-03 0.344051 0.560666 2020-06-04 -1.660631 0.320610 2020-06-05 1.241433 -0.657050 2020-06-06 0.533364 1.888093
loc[行名选择, 列名选择],未指定行名或列名,或者指定为:则表示选择当前所有行,或列
a -1.365774
b 1.169899
c 0.607591
d -2.029687
Name: 2020-06-01 00:00:00, dtype: float64
1 df.loc['2020-06-01' , 'b' ]
1.1698991845802456
2020-06-01 1.169899
2020-06-02 -0.800448
2020-06-03 0.560666
2020-06-04 0.320610
2020-06-05 -0.657050
2020-06-06 1.888093
Freq: D, Name: b, dtype: float64
a b 2020-06-01 -1.365774 1.169899 2020-06-02 -0.967683 -0.800448 2020-06-03 1.790609 0.560666 2020-06-04 2.068663 0.320610 2020-06-05 -0.956351 -0.657050 2020-06-06 -1.135870 1.888093
-1.3657744117360429
a -1.365774
b 1.169899
c 0.607591
d -2.029687
Name: 2020-06-01 00:00:00, dtype: float64
只有当布尔表达式为真时的数据才会被选择
a b c d 2020-06-03 1.790609 0.560666 0.344051 0.799520 2020-06-04 2.068663 0.320610 -1.660631 0.416631
1 df[(df['a' ] > 1 ) & (df['d' ] <0 )]
1 2 df.loc['2020-06-01' , 'a' ] = np.nan df.loc['2020-06-06' , 'c' ] = np.nan
a b c d 2020-06-01 NaN 1.169899 0.607591 -2.029687 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 2020-06-03 1.790609 0.560666 0.344051 0.799520 2020-06-04 2.068663 0.320610 -1.660631 0.416631 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 2020-06-06 -1.135870 1.888093 NaN 0.080852
1 df['e' ] = np.where((df['a' ] > 1 ) & (df['d' ]<0 ), 1 , 0 )
a b c d e 2020-06-01 NaN 1.169899 0.607591 -2.029687 0 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 0 2020-06-03 1.790609 0.560666 0.344051 0.799520 0 2020-06-04 2.068663 0.320610 -1.660631 0.416631 0 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 0 2020-06-06 -1.135870 1.888093 NaN 0.080852 0
1 2 tmp = df.copy() df.loc[:,'f' ] = tmp.apply(lambda row: row['b' ]+ row['d' ], axis=1 )
a b c d e f 2020-06-01 NaN 1.169899 0.607591 -2.029687 0 -0.859788 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 0 -0.100111 2020-06-03 1.790609 0.560666 0.344051 0.799520 0 1.360186 2020-06-04 2.068663 0.320610 -1.660631 0.416631 0 0.737241 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 0 -1.309546 2020-06-06 -1.135870 1.888093 NaN 0.080852 0 1.968945
a b c d e f 2020-06-01 NaN 1.169899 0.607591 -2.029687 0 -0.859788 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 0 -0.100111 2020-06-03 1.790609 0.560666 0.344051 0.799520 0 1.360186 2020-06-04 2.068663 0.320610 -1.660631 0.416631 0 0.737241 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 0 -1.309546 2020-06-06 -1.135870 1.888093 NaN 0.080852 0 1.968945
1 2 df.replace([1 ,3 ],['one' ,'three' ])
a b c d e f 2020-06-01 NaN 1.169899 0.607591 -2.029687 0 -0.859788 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 0 -0.100111 2020-06-03 1.790609 0.560666 0.344051 0.799520 0 1.360186 2020-06-04 2.068663 0.320610 -1.660631 0.416631 0 0.737241 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 0 -1.309546 2020-06-06 -1.135870 1.888093 NaN 0.080852 0 1.968945
1 df.rename(columns={'c' :'cc' })
a b cc d e f 2020-06-01 NaN 1.169899 0.607591 -2.029687 0 -0.859788 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 0 -0.100111 2020-06-03 1.790609 0.560666 0.344051 0.799520 0 1.360186 2020-06-04 2.068663 0.320610 -1.660631 0.416631 0 0.737241 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 0 -1.309546 2020-06-06 -1.135870 1.888093 NaN 0.080852 0 1.968945
b c d e f a NaN 1.169899 0.607591 -2.029687 0 -0.859788 -0.967683 -0.800448 0.123673 0.700337 0 -0.100111 1.790609 0.560666 0.344051 0.799520 0 1.360186 2.068663 0.320610 -1.660631 0.416631 0 0.737241 -0.956351 -0.657050 1.241433 -0.652496 0 -1.309546 -1.135870 1.888093 NaN 0.080852 0 1.968945
1 df.drop(columns=['a' , 'f' ])
b c d e 2020-06-01 1.169899 0.607591 -2.029687 0 2020-06-02 -0.800448 0.123673 0.700337 0 2020-06-03 0.560666 0.344051 0.799520 0 2020-06-04 0.320610 -1.660631 0.416631 0 2020-06-05 -0.657050 1.241433 -0.652496 0 2020-06-06 1.888093 NaN 0.080852 0
a b c d e f 2020-06-01 True False False False False False 2020-06-02 False False False False False False 2020-06-03 False False False False False False 2020-06-04 False False False False False False 2020-06-05 False False False False False False 2020-06-06 False False True False False False
a b c d e f 2020-06-01 False True True True True True 2020-06-02 True True True True True True 2020-06-03 True True True True True True 2020-06-04 True True True True True True 2020-06-05 True True True True True True 2020-06-06 True True False True True True
a b c d e f 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 0 -0.100111 2020-06-03 1.790609 0.560666 0.344051 0.799520 0 1.360186 2020-06-04 2.068663 0.320610 -1.660631 0.416631 0 0.737241 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 0 -1.309546
a b c d e f 2020-06-01 1000.000000 1.169899 0.607591 -2.029687 0 -0.859788 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 0 -0.100111 2020-06-03 1.790609 0.560666 0.344051 0.799520 0 1.360186 2020-06-04 2.068663 0.320610 -1.660631 0.416631 0 0.737241 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 0 -1.309546 2020-06-06 -1.135870 1.888093 1000.000000 0.080852 0 1.968945
a b c d e f 2020-06-01 0.159874 1.169899 0.607591 -2.029687 0 -0.859788 2020-06-02 -0.967683 -0.800448 0.123673 0.700337 0 -0.100111 2020-06-03 1.790609 0.560666 0.344051 0.799520 0 1.360186 2020-06-04 2.068663 0.320610 -1.660631 0.416631 0 0.737241 2020-06-05 -0.956351 -0.657050 1.241433 -0.652496 0 -1.309546 2020-06-06 -1.135870 1.888093 0.131223 0.080852 0 1.968945
a 0.159874
b 0.413628
c 0.131223
d -0.114141
e 0.000000
f 0.299488
dtype: float64
a b c d e f a 1.000000 0.101781 -0.680085 0.508954 NaN 0.318586 b 0.101781 1.000000 -0.171353 -0.266608 NaN 0.587598 c -0.680085 -0.171353 1.000000 -0.437212 NaN -0.605077 d 0.508954 -0.266608 -0.437212 1.000000 NaN 0.623208 e NaN NaN NaN NaN NaN NaN f 0.318586 0.587598 -0.605077 0.623208 NaN 1.000000
a 5
b 6
c 5
d 6
e 6
f 6
dtype: int64
a 2.068663
b 1.888093
c 1.241433
d 0.799520
e 0.000000
f 1.968945
dtype: float64
a -1.135870
b -0.800448
c -1.660631
d -2.029687
e 0.000000
f -1.309546
dtype: float64
a -0.956351
b 0.440638
c 0.344051
d 0.248741
e 0.000000
f 0.318565
dtype: float64
a 1.620114
b 1.038903
c 1.085770
d 1.074899
e 0.000000
f 1.280342
dtype: float64
1 2 3 4 5 df4 = df3.sort_values(['country' ,'score' ],ascending=[1 , 0 ],inplace=False ) df4
name age gender score country 5 Jack 18 M 88 CN 6 Tim 27 F 67 CN 3 Jake 24 M 62 CN 1 Molly 32 F 94 US 4 Amy 23 F 70 US 2 Tina 36 F 57 US 0 Jason 20 F 25 US
1 2 df4.groupby(['country' ]).head(2 )
name age gender score country 5 Jack 18 M 88 CN 6 Tim 27 F 67 CN 1 Molly 32 F 94 US 4 Amy 23 F 70 US
1 2 3 4 5 df5 = df3.sort_values(['country' ,'gender' , 'score' ],ascending=[1 , 0 , 0 ],inplace=False ) df5
name age gender score country 5 Jack 18 M 88 CN 3 Jake 24 M 62 CN 6 Tim 27 F 67 CN 1 Molly 32 F 94 US 4 Amy 23 F 70 US 2 Tina 36 F 57 US 0 Jason 20 F 25 US
1 2 df5 = df5.groupby(['country' , 'gender' ]).head(1 ) df5
name age gender score country 5 Jack 18 M 88 CN 6 Tim 27 F 67 CN 1 Molly 32 F 94 US
1 df5.groupby(['country' ]).head(2 )
name age gender score country 5 Jack 18 M 88 CN 6 Tim 27 F 67 CN 1 Molly 32 F 94 US
1 2 3 scoreMean = df3.groupby(['gender' ])['score' ].mean() scoreMean = pd.DataFrame(scoreMean) scoreMean
1 2 df3.merge(scoreMean,left_on='gender' ,right_index=True )
name age gender score_x country score_y 0 Jason 20 F 25 US 62.6 1 Molly 32 F 94 US 62.6 2 Tina 36 F 57 US 62.6 4 Amy 23 F 70 US 62.6 6 Tim 27 F 67 CN 62.6 3 Jake 24 M 62 CN 75.0 5 Jack 18 M 88 CN 75.0
name age gender score country 0 Jason 20 F 25 US 1 Molly 32 F 94 US 2 Tina 36 F 57 US 3 Jake 24 M 62 CN 4 Amy 23 F 70 US 5 Jack 18 M 88 CN 6 Tim 27 F 67 CN
1 df3.groupby(['country' ])['gender' ].count().to_frame()
1 2 3 df3.groupby(['country' , 'gender' ])['gender' ].count().to_frame()
gender country gender CN F 1 M 2 US F 4
1 df3.groupby(['country' ])['gender' ].nunique().to_frame()
1 2 df3.groupby('country' ).sum ()
age score country CN 69 217 US 111 246
1 2 df3.groupby('country' )['score' ].sum ()
country
CN 217
US 246
Name: score, dtype: int64
1 import matplotlib.pyplot as plt
1 2 3 plt.clf() df3.groupby('country' ).sum ().plot(kind='bar' ) plt.show()
<Figure size 432x288 with 0 Axes>
1 df3.groupby('country' )['score' ].sum ().plot(kind='bar' )
<matplotlib.axes._subplots.AxesSubplot at 0x7f040a967a90>
1 df3.groupby('country' ).agg({'score' :['min' ,'max' ,'mean' ]})
score min max mean country CN 62 88 72.333333 US 25 94 61.500000
1 2 df3.groupby('country' )['score' ].agg([np.min , np.max , np.mean])
amin amax mean country CN 62 88 72.333333 US 25 94 61.500000
1 2 df3.groupby('country' ).agg({'score' : ['max' ,'min' , 'std' ], 'age' : ['sum' , 'count' , 'max' ]})
score age max min std sum count max country CN 88 62 13.796135 69 3 27 US 94 25 28.757608 111 4 36
1 2 3 4 t1=df3.groupby('country' )['score' ].mean().to_frame() t2 = df3.groupby('country' )['age' ].sum ().to_frame() t1.merge(t2,left_index=True ,right_index=True )
score age country CN 72.333333 69 US 61.500000 111
1 2 3 4 grouped = df3.groupby('country' ) for name,group in grouped: print(name) print(group)
CN
name age gender score country
3 Jake 24 M 62 CN
5 Jack 18 M 88 CN
6 Tim 27 F 67 CN
US
name age gender score country
0 Jason 20 F 25 US
1 Molly 32 F 94 US
2 Tina 36 F 57 US
4 Amy 23 F 70 US
1 2 3 4 grouped = df3.groupby(['country' , 'gender' ]) for name,group in grouped: print(name) print(group)
('CN', 'F')
name age gender score country
6 Tim 27 F 67 CN
('CN', 'M')
name age gender score country
3 Jake 24 M 62 CN
5 Jack 18 M 88 CN
('US', 'F')
name age gender score country
0 Jason 20 F 25 US
1 Molly 32 F 94 US
2 Tina 36 F 57 US
4 Amy 23 F 70 US
1 df3.groupby('country' ).groups
{'CN': Int64Index([3, 5, 6], dtype='int64'),
'US': Int64Index([0, 1, 2, 4], dtype='int64')}
1 df3.groupby('country' ).get_group('CN' )
name age gender score country 3 Jake 24 M 62 CN 5 Jack 18 M 88 CN 6 Tim 27 F 67 CN
1 df3.groupby('name' ).filter (lambda x: len (x) >= 3 )
name age gender score country
1 2 3 4 5 df3.pivot(index ='name' ,columns='gender' ,values=['score' ,'age' ])
score age gender F M F M name Amy 70.0 NaN 23.0 NaN Jack NaN 88.0 NaN 18.0 Jake NaN 62.0 NaN 24.0 Jason 25.0 NaN 20.0 NaN Molly 94.0 NaN 32.0 NaN Tim 67.0 NaN 27.0 NaN Tina 57.0 NaN 36.0 NaN
1 2 3 4 pd.pivot_table(df3,index=['country' , 'gender' ], values=['score' ],aggfunc=np.sum )
score country gender CN F 67 M 150 US F 246
1 pd.pivot_table(df3,index=['country' , 'gender' ], values=['score' , 'age' ],aggfunc=[np.sum , np.mean],fill_value=0 ,margins=True )
sum mean age score age score country gender CN F 27 67 27.000000 67.000000 M 42 150 21.000000 75.000000 US F 111 246 27.750000 61.500000 All 180 463 25.714286 66.142857
name age gender score country 0 Jason 20 F 25 US 1 Molly 32 F 94 US 2 Tina 36 F 57 US 3 Jake 24 M 62 CN 4 Amy 23 F 70 US 5 Jack 18 M 88 CN 6 Tim 27 F 67 CN
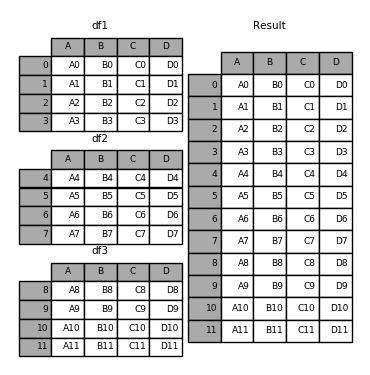
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 t1 = pd.DataFrame({'A' : ['A0' , 'A1' , 'A2' , 'A3' ], 'B' : ['B0' , 'B1' , 'B2' , 'B3' ], 'C' : ['C0' , 'C1' , 'C2' , 'C3' ], 'D' : ['D0' , 'D1' , 'D2' , 'D3' ]}, index=[0 , 1 , 2 , 3 ]) print('-----t1----' ) print(t1) t2 = pd.DataFrame({'A' : ['A4' , 'A5' , 'A6' , 'A7' ], 'B' : ['B4' , 'B5' , 'B6' , 'B7' ], 'C' : ['C4' , 'C5' , 'C6' , 'C7' ], 'D' : ['D4' , 'D5' , 'D6' , 'D7' ]}, index=[4 , 5 , 6 , 7 ]) print('----t2-----' ) print(t2) t3 = pd.DataFrame({'A' : ['A8' , 'A9' , 'A10' , 'A11' ], 'B' : ['B8' , 'B9' , 'B10' , 'B11' ], 'C' : ['C8' , 'C9' , 'C10' , 'C11' ], 'D' : ['D8' , 'D9' , 'D10' , 'D11' ]}, index=[8 , 9 , 10 , 11 ]) print('-----t3----' ) print(t2) frames = [t1, t2, t3] pd.concat(frames)
-----t1----
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
----t2-----
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
-----t3----
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
A B C D 0 A0 B0 C0 D0 1 A1 B1 C1 D1 2 A2 B2 C2 D2 3 A3 B3 C3 D3 4 A4 B4 C4 D4 5 A5 B5 C5 D5 6 A6 B6 C6 D6 7 A7 B7 C7 D7 8 A8 B8 C8 D8 9 A9 B9 C9 D9 10 A10 B10 C10 D10 11 A11 B11 C11 D11
1 2 3 Image(url="http://static.cyub.vip/images/202001/pandas.concat.png" )
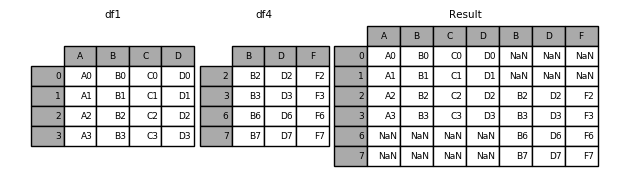
1 2 3 4 5 6 7 8 t4 = pd.DataFrame({'B' : ['B2' , 'B3' , 'B6' , 'B7' ], 'D' : ['D2' , 'D3' , 'D6' , 'D7' ], 'F' : ['F2' , 'F3' , 'F6' , 'F7' ]}, index=[2 , 3 , 6 , 7 ]) print('-----t4----' ) pd.concat([t1, t4], axis=1 , sort=False )
-----t4----
A B C D B D F 0 A0 B0 C0 D0 NaN NaN NaN 1 A1 B1 C1 D1 NaN NaN NaN 2 A2 B2 C2 D2 B2 D2 F2 3 A3 B3 C3 D3 B3 D3 F3 6 NaN NaN NaN NaN B6 D6 F6 7 NaN NaN NaN NaN B7 D7 F7
1 Image(url="http://static.cyub.vip/images/202001/pandas.concat.outer_join.png" )
1 pd.concat([t1, t4], axis=1 , join='inner' )
A B C D B D F 2 A2 B2 C2 D2 B2 D2 F2 3 A3 B3 C3 D3 B3 D3 F3
1 Image(url="http://static.cyub.vip/images/202001/pandas.concat.inner_join.png" )
A B C D 0 A0 B0 C0 D0 1 A1 B1 C1 D1 2 A2 B2 C2 D2 3 A3 B3 C3 D3 4 A4 B4 C4 D4 5 A5 B5 C5 D5 6 A6 B6 C6 D6 7 A7 B7 C7 D7 8 A8 B8 C8 D8 9 A9 B9 C9 D9 10 A10 B10 C10 D10 11 A11 B11 C11 D11
join(on=None, how=‘left’, lsuffix=’’, rsuffix=’’, sort=False)
on:join的键,默认是矩阵的index, how:join方式,left-相当于左连接,outer,inner
更多查看Database-style DataFrame or named Series joining/merging
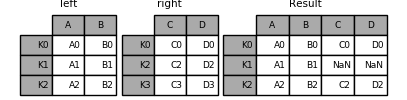
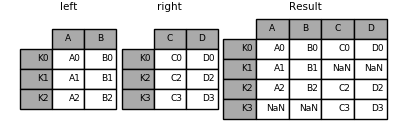
1 2 3 4 5 6 7 8 9 10 11 12 13 14 left = pd.DataFrame({'A' : ['A0' , 'A1' , 'A2' ], 'B' : ['B0' , 'B1' , 'B2' ]}, index=['K0' , 'K1' , 'K2' ]) print('----left----' ) print(left) right = pd.DataFrame({'C' : ['C0' , 'C2' , 'C3' ], 'D' : ['D0' , 'D2' , 'D3' ]}, index=['K0' , 'K2' , 'K3' ]) print('---right----' ) print(right) left.join(right)
----left----
A B
K0 A0 B0
K1 A1 B1
K2 A2 B2
---right----
C D
K0 C0 D0
K2 C2 D2
K3 C3 D3
A B C D K0 A0 B0 C0 D0 K1 A1 B1 NaN NaN K2 A2 B2 C2 D2
1 Image(url="http://static.cyub.vip/images/202001/pandas.join.left.png" )
1 left.join(right, how='outer' )
A B C D K0 A0 B0 C0 D0 K1 A1 B1 NaN NaN K2 A2 B2 C2 D2 K3 NaN NaN C3 D3
1 Image(url="http://static.cyub.vip/images/202001/pandas.join.outer.png" )
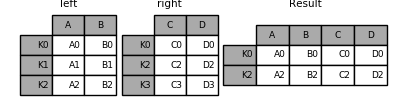
1 left.join(right, how='inner' )
1 Image(url="http://static.cyub.vip/images/202001/pandas.join.inner.png" )
left.join(right, on=key_or_keys)= pd.merge(left, right, left_on=key_or_keys, right_index=True,
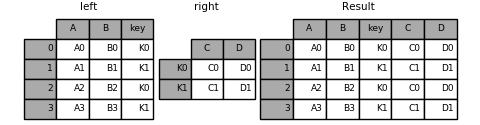
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 left = pd.DataFrame({'A' : ['A0' , 'A1' , 'A2' , 'A3' ], 'B' : ['B0' , 'B1' , 'B2' , 'B3' ], 'key' : ['K0' , 'K1' , 'K0' , 'K1' ]}) print('----left----' ) print(left) right = pd.DataFrame({'C' : ['C0' , 'C1' ], 'D' : ['D0' , 'D1' ]}, index=['K0' , 'K1' ]) print('----right----' ) print(right) left.join(right, on='key' )
----left----
A B key
0 A0 B0 K0
1 A1 B1 K1
2 A2 B2 K0
3 A3 B3 K1
----right----
C D
K0 C0 D0
K1 C1 D1
A B key C D 0 A0 B0 K0 C0 D0 1 A1 B1 K1 C1 D1 2 A2 B2 K0 C0 D0 3 A3 B3 K1 C1 D1
1 Image(url="http://static.cyub.vip/images/202001/pandas.join.key.left.png" )
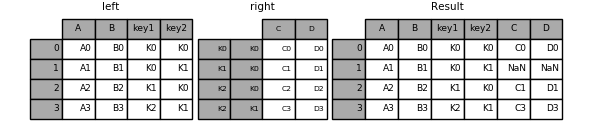
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 left = pd.DataFrame({'A' : ['A0' , 'A1' , 'A2' , 'A3' ], 'B' : ['B0' , 'B1' , 'B2' , 'B3' ], 'key1' : ['K0' , 'K0' , 'K1' , 'K2' ], 'key2' : ['K0' , 'K1' , 'K0' , 'K1' ]}) print('----left----' ) print(left) index = pd.MultiIndex.from_tuples([('K0' , 'K0' ), ('K1' , 'K0' ), ('K2' , 'K0' ), ('K3' , 'K11' )]) right = pd.DataFrame({'C' : ['C0' , 'C1' , 'C2' , 'C3' ], 'D' : ['D0' , 'D1' , 'D2' , 'D3' ]}, index=index) print('----right----' ) print(right) left.join(right, on=['key1' , 'key2' ])
----left----
A B key1 key2
0 A0 B0 K0 K0
1 A1 B1 K0 K1
2 A2 B2 K1 K0
3 A3 B3 K2 K1
----right----
C D
K0 K0 C0 D0
K1 K0 C1 D1
K2 K0 C2 D2
K3 K11 C3 D3
A B key1 key2 C D 0 A0 B0 K0 K0 C0 D0 1 A1 B1 K0 K1 NaN NaN 2 A2 B2 K1 K0 C1 D1 3 A3 B3 K2 K1 NaN NaN
1 Image(url="http://static.cyub.vip/images/202001/pandas.join.keys.left.png" )
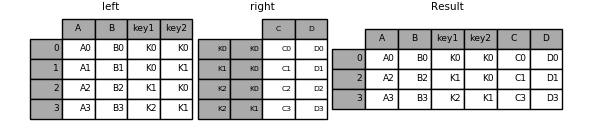
1 left.join(right, on=['key1' , 'key2' ], how='inner' )
A B key1 key2 C D 0 A0 B0 K0 K0 C0 D0 2 A2 B2 K1 K0 C1 D1
1 Image(url="http://static.cyub.vip/images/202001/pandas.join.keys.inner.png" )
1 pd.read_csv('../dataset/game_daily_stats_20200127_20200202.csv' , names=['id' , '日期' , '游戏id' , '游戏名称' , '国家' , '国家码' , '下载数' , '下载用户数' , '成功下载数' , '成功下载用户数' ,'安装数' , '安装用户数' ],na_filter = False )
id 日期 游戏id 游戏名称 国家 国家码 下载数 下载用户数 成功下载数 成功下载用户数 安装数 安装用户数 0 7564316 2020-01-27 1 Uphill Rush Water Park Racing 俄罗斯 RU 1 1 1 1 1 1 1 7564317 2020-01-27 1 Uphill Rush Water Park Racing 肯尼亚 KE 2 2 2 2 0 0 2 7564318 2020-01-27 1 Uphill Rush Water Park Racing 刚果金 CD 1 1 0 0 0 0 3 7564319 2020-01-27 1 Uphill Rush Water Park Racing 尼泊尔 NP 1 1 0 0 0 0 4 7564320 2020-01-27 1 Uphill Rush Water Park Racing 索马里 SO 1 1 1 1 1 1 ... ... ... ... ... ... ... ... ... ... ... ... ... 179886 8010481 2020-02-02 175 Soccer Star 2022 World Legend: Football game 赞比亚 ZM 2 2 0 0 0 0 179887 8010482 2020-02-02 175 Soccer Star 2022 World Legend: Football game 尼日利亚 NG 1 1 2 2 2 2 179888 8010483 2020-02-02 175 Soccer Star 2022 World Legend: Football game 埃及 EG 2 2 0 0 0 0 179889 8010484 2020-02-02 175 Soccer Star 2022 World Legend: Football game 科特迪瓦 CI 3 3 2 2 2 2 179890 8010485 2020-02-02 175 Soccer Star 2022 World Legend: Football game 约旦 JO 1 1 0 0 0 0
179891 rows × 12 columns
1 df.to_csv('/tmp/pandas.csv' , encoding="utf_8_sig" )