TCP内核参数调优
调整全连接队列长度
TCP 建立连接时要经过 3 次握手,在客户端向服务器发起连接时,
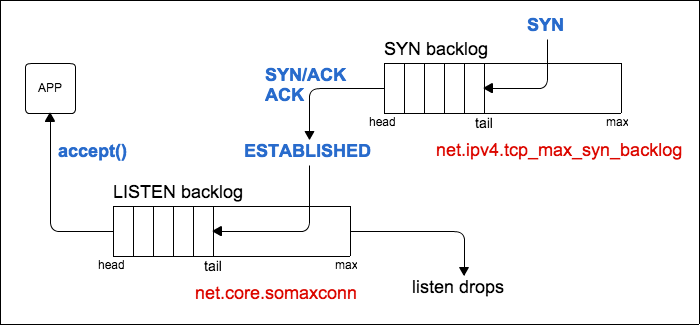
对于服务器而言,一个完整的连接建立过程,服务器会经历 2 种 TCP 状态:SYN_REVD, ESTABELLISHED。对应也会维护两个队列:
- 一个存放SYN的队列(半连接队列,也成SYN队列)
- 一个存放已经完成连接的队列(全连接队列, 也称Accept队列)
当一个连接的状态是 SYN RECEIVED 时,它会被放在 SYN 队列中。
当它的状态变为 ESTABLISHED 时,它会被转移到另一个队列。应用程序只从已完成的连接的队列中获取请求。
全连接队列长度如何计算?
对于Linux系统上的服务程序(比如nginx、php-fpm等应用程序),都会使用同一个底层系统调用API来监听端口。listen中的backlog参数,设置了应用程序全连接队列长度。应用程序的全队列长度,影响了可以接受的并发请求的最大值。
1 |
|
应用程序的全队列长度除依赖于程序本身listen中的backlog,还依赖系统内核中net.core.somaxconn参数,即应用程序的全队列长度取backlog和net.core.somaxconn中最小值。
对高并发访问的应用,如果只增加应用层的backlog是不够,还要注意系统内核中队列设置,linux系统默认值都是不会太大。比如Ubuntu 16中net.core.somaxconn默认值是128。
我们可以通过下面方式,查看系统内核参数大小:
1 | cat /proc/sys/net/core/somaxconn |
通过以下方式调整内核参数大小
1 | sudo sysctl -w net.core.somaxconn=32768 |
注意:上面方式更改之后,会立即生效,但服务器重启之后会恢复到默认值。我们可以通过以下方式,永久性更改:
1 | echo 'net.core.somaxconn=32768' >> /etc/sysctl.conf |
半连接队列长度如何计算?
半连接队列长度由内核参数 tcp_max_syn_backlog 决定,
当使用 SYN Cookie 时(即内核参数 net.ipv4.tcp_syncookies = 1时候),半连接对垒长度不能大于长连接长度
半连接队列长度 = min(应用层的backlog, 内核参数net.core.somaxconn,内核参数tcp_max_syn_backlog)
查看队列溢出
高并发访问情况,若应用程序处理不过来,就会造成SYN/Accept队列溢出,我们可以通过以下方式查看溢出情况:
- 查看SYN队列溢出
1 | netstat -s | grep LISTEN |
- 查看ACCEPT队列溢出
1 | netstat -s | grep TCPBacklogDrop |
查看应用的全连接队列最大长度
应用的backlog调整之后,我们可以通过ss命令查看调整结果:
1 | ss -ln |
在LISTEN状态,其中 Send-Q 即为Accept queue的最大值,Recv-Q 则表示全连接队列中等待被服务器accept()。从上面我们可以看出Nginx(80端口)的全连接队列长度是511,PHP-FPM(9000端口)全连接队列长度是128
注意: 调整net.core.somaxconn参数之后,一定要重启应用。比如Nginx, PHP-FPM默认的backlog都是511,若此前服务器net.core.somaxconn参数是128。则Nginx,FPM的全连接队列长度就是128。此时调整``net.core.somaxconn`参数值1024,对内核来说是立即生效的。但对Nginx,FPM主进程早已经启动,最大队列长度还是128。所以需要我们手动启动应用主进程
1 | sudo sysytemctl restart nginx |
调整本地端口范围,防止端口资源耗尽
默认情况本地端口范围不足3万,对于高并发服务器,有时候是不够的,之前我们项目中峰值qps达到3.5k时候出现Cannot assign requested address。查看项目日志分析原因是大量连接Redis时候,此时项目服务器作为客户端,端口资源大量处理TIME_WAIT状态,导致端口资源使用完了。解决这个问题一个手段就是调整端口范围。
查看端口范围:
1 | cat /proc/sys/net/ipv4/ip_local_port_range |
调整端口范围:
1 | echo 'net.ipv4.ip_local_port_range = 1024 65000' > /proc/sys/net/ipv4/ip_local_port_range |
开启tcp_syncookies,增强抗SYN Flood的能力
TCP连接建立时,客户端通过发送SYN报文发起向处于监听状态的服务器发起连接,服务器为该连接分配一定的资源,并发送SYN+ACK报文。对服务器来说,此时该连接的状态称为半连接(Half-Open),而当其之后收到客户端回复的ACK报文后,连接才算建立完成。在这个过程中,如果服务器一直没有收到ACK报文(比如在链路中丢失了),服务器会在超时后重传SYN+ACK。
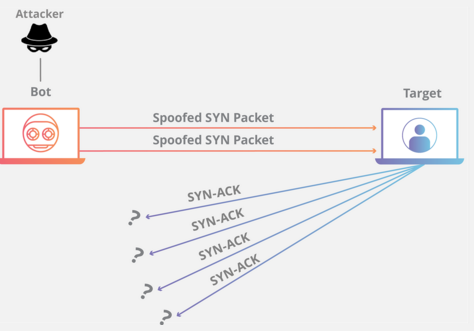
但是如果有坏人故意大量不断发送伪造的SYN报文,那么服务器就会分配大量注定无用的资源,并且从backlog的意义 中可知,服务器能保存的半连接的数量是有限的!所以当服务器受到大量攻击报文时,它就不能再接收正常的连接了。换句话说,它的服务不再可用了!这就是SYN Flood攻击的原理,它是一种典型的DDoS攻击。
SYN Cookie技术可以让服务器在SYN队列溢出时候,在收到客户端的SYN报文时,不再分配资源保存客户端信息,而是将这些信息保存在SYN+ACK的初始序号和时间戳中。对正常的连接,这些信息会随着ACK报文被带回来。SYN Cookie是通过参数tcp_syncookies开启。
1 | cat /proc/sys/net/ipv4/tcp_syncookies // 查看是否开启tcp_syncookies |
其他内核参数优化
-
net.ipv4.tcp_tw_reuse = 1
默认值是0,表示关闭。开启之后允许将TIME_WAIT socket重新用于新的TCP连接。开启后,有助于解决
Cannot assign requested address等time_wait过多造成的问题。 -
net.ipv4.tcp_tw_recycle = 1
默认值是0,表示关闭。表示开启TCP连接中TIME_WAIT socket的快速回收。
-
net.ipv4.tcp_fin_timeout = 30
如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间
-
net.ipv4.tcp_keepalive_time = 1200
默认值是2小时,表示当Keepalived启用时候,TCP发送Keepalived消息的平度,改为20分钟
-
net.ipv4.tcp_max_syn_backlog = 8192
默认值是1024,表示SYN队列的长度,增大队列长队值值8192,可以容纳更多等待连接的网络连接数。
-
net.ipv4.tcp_synack_retries = 1
默认值5,表示重发5次,每次等待30~40秒,即半连接默认时间大约为180秒。客户端connect()返回不代表TCP连接建立成功,有可能此时accept queue 已满,系统会直接丢弃后续ACK请求;客户端误以为连接已建立,开始调用等待至超时;服务器则等待ACK超时,会重传SYN+ACK 给客户端,重传次数为
net.ipv4.tcp_synack_retries -
net.core.netdev_max_backlog = 4096
每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。 -
net.ipv4.tcp_max_tw_buckets = 5000
表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。默认为180000,改为 5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量,但是对于Squid,效果却不大。此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死
Nginx配置调优
工作进程
NGINX可以运行多个工作进程,每个工作进程都能够处理大量的同时连接。我们可以控制工作进程的数量以及它们处理最大连接数:
-
worker_processes
work_processes设置Nginx工作进程数,默认是1。最佳配置是有几个cpu,就配置几个工作进程,可以通过设置
auto自动侦探cpu个数来实现。1
worker_processes auto;
-
worker_connections
worker_connections设置每个工作进程可以同时处理的最大连接数。默认值为512。对于高并发情况下,这个有点小。
1
worker_connections 2048;
注意同时连接的实际数量不能超过打开文件最大数量的当前限制,即worker_rlimit_nofile指令的限制。
若worker_connections设置过小此时nginx错误日志会报下面错误:
1 | 2019/12/31 09:01:22 [alert] 6215#6215: *60878 768 worker_connections are not enough while connecting to upstream, client: 192.168.33.1, server: , request: "GET /api/v2/cats?page=1&size=99&lang=zh HTTP/1.0", upstream: "fastcgi://unix:/var/run/php/php7.1-fpm.sock:", host: "192.168.33.10:9969" |
-
worker_rlimit_nofile
用于限制工作进程最大打开文件数(RLIMIT_NOFILE)。此指令可以在不重启主进程生效。
1
worker_rlimit_nofile 65535;
在调整work_connetions设置之后,如果未调整此指令值,高并发情况下,Nginx错误日志里面会报下面错误:
1
2019/12/31 09:52:30 [alert] 7122#7122: *21193 socket() failed (24: Too many open files) while connecting to upstream, client: 192.168.33.10, server: , request: "GET /api/v2/cats?page=1&size=99&lang=zh HTTP/1.0", upstream: "fastcgi://unix:/var/run/php/php7.1-fpm.sock:", host: "192.168.33.10:9969"
backlog设置
Nginx默认监听的backlog是512,如果队列满了,客户端再进行请求时候,会收到连接拒绝(Connection refused)。在高并发访问情况下,我们可以调整至8192。
1 | listen 80 backlog=8192; |
PHP-FPM配置调优
- 调整backlog配置
fpm默认backlog大小是511,对于高并发应用,这个值有点低。我们可以根据FPM的能支持的QPS来调整中,即backlog = QPS。
1 | listen.backlog = 1024 |
若发现nginx报告如下错误:
1 | connect() to unix:/var/run/php/php7.1-fpm.sock failed (11: Resource temporarily unavailable) while connecting to upstream, client: 192.168.33.1, server: , request: "GET /api/ |
往往说明fpm backlog设置太小。
注意:
fpm的backlog并不是越大越好。fpm的backlog太大,会导致大量请求在fpm这边堆集,处理不过来,最终nginx会等待超时,报错504 gateway timeout错误,同时等fpm处理完准备write 数据给nginx时,发现TCP连接断开了,报Broken pipe错误。
fpm的backlog太小的话,会导致nginx代理过来的请求,根本进入不了php-fpm的全队列,报502 Bad Gateway错误。
调整fpm的backlog时候,注意调整系统内核的TCP全队列长度是否大于backlog。
对于内核参数,Nginx,FPM等调优过程中,需要不断测试调优,先使用系统默认参数,逐个参数调整,然后进行ab压测, 观察压测的qps,异常等信息,结合nginx日志,fpm日志来定位参数调整后情况
1 | ab -n 10000 -c 500 "http://192.168.33.10:9969/api/v2/cats?page=1&size=99&lang=zh" |